8.10. S3 überwachen¶
Sie können den S3-Cluster und dessen Komponenten auf der Anzeige Storage-Services –> S3 –> Überblick mit den folgenden Diagrammen überwachen:
- Verfügbarkeit von Namensserver- (NS), Betriebssystem- (OS) und Gateway- (GW) Services. Wenn ein S3-GW-Service den Status ‚Fehlgeschlagen‘ hat, ist höchstwahrscheinlich der Knoten, der ihn hostet, ausgefallen. Dies ist für den S3-Cluster nicht kritisch: die Hochverfügbarkeit des S3-Service basiert auf den DNS-Einträgen. Wenn die DNS-Einträge richtig konfiguriert wurden, bleibt der S3-Service für S3-Clients voll zugänglich. Wenn jedoch ein OS- oder NS-Service ausfällt, ist dies kritisch: der komplette S3-Cluster kann dann nicht normal funktionieren. Wenn Sie sehen, dass einige der NS- oder OS-Services offline sind, jedoch alle Cluster-Knoten intakt sind und das Netzwerk mit dem Traffic-Typ OSTOR privat gut arbeitet, können Sie sich an den technische Support wenden. Sie können auch die Grafana-Dashboards heranziehen, um die Ursachen für den Ausfall zu ermitteln.
- Operationsrate. Das Diagramm zeigt die gesamte Cluster-Last, die durch die Anfragen von S3-Benutzern entsteht, inkl. aller Aktionstypen.
- Anfragefehlerrate. Die Anfragen werden von Benutzern oder deren Applikationen generiert. Einige Anfragen können nicht verarbeitet werden: Es können z.B. nicht existierende Objekte angefordert werden, nicht übereinstimmende Zugriffsrechte vorliegen oder nicht unterstützte Funktionen verwendet werden (siehe: Unterstützte Amazon S3-Funktionen). Es ist also normal, wenn die Fehlerrate einen kleinen Anteil an der gesamten Operationsrate ausmacht. Sie kann jedoch auch darauf hindeuten, dass die für den Zugriff verwendete S3-Applikation nicht ordnungsgemäß funktioniert. Wenn der S3-Cluster zudem für öffentliche Zugriffe verfügbar ist, kann er darüber hinaus von Internet-Crawlern gescannt werden. In diesem Fall können die Fehlerspitzen die Probleme mit deren nicht passenden Zugriffsrechten widerspiegeln. Für den Cluster ist das jedoch kein kritisches Problem.
- Bandbreite. Das Diagramm zeigt die gesamte Cluster-Last, die durch die Anfragen von S3-Benutzern entsteht.
- PUT-Latenz und GET-Latenz. Diese Werte werden ab dem Zeitpunkt gemessen, an dem das letzte Byte der Benutzeranfrage empfangen wurde, bis zu dem Zeitpunkt, an dem das erste Byte der Antwort gesendet wurde.
8.10.1. Erweitertes S3-Monitoring über Grafana¶
Gehen Sie für eine erweiterte Überwachung des S3-Clusters zur Anzeige Storage-Services –> S3 –> Überblick und klicken Sie dann auf Grafana Dashboard. Es wird eine separate Webbrowser-Registerkarte mit vorkonfigurierten Grafana Dashboards geöffnet. Sie können für jedes Diagramm eine detaillierte Beschreibung erhalten, wenn Sie in dessen linken Ecke auf das i-Symbol klicken.
Verwenden Sie für eine ausführliche Überwachung der OS- und NS-Services die Dashboards Object Storage-Überblick, Objekt-Storage-OS-Details sowie Objekt-Storage-NS-Details. Filtern Sie die Daten nach Knoten oder Volumes, um diejenigen mit abweichender Service-Nutzung zu erkennen. Beachten Sie das Diagramm Task-Verzögerungen: es zeigt den Anteil der aufgebrachten Zeit an, um auf die CPU, den verfügbaren Arbeitsspeicher (bzw. dessen Freigabe), den Speichertransfer aus dem Swap-Bereich („Swap-in“) und den Abschluss der I/O-Operationen zu warten.
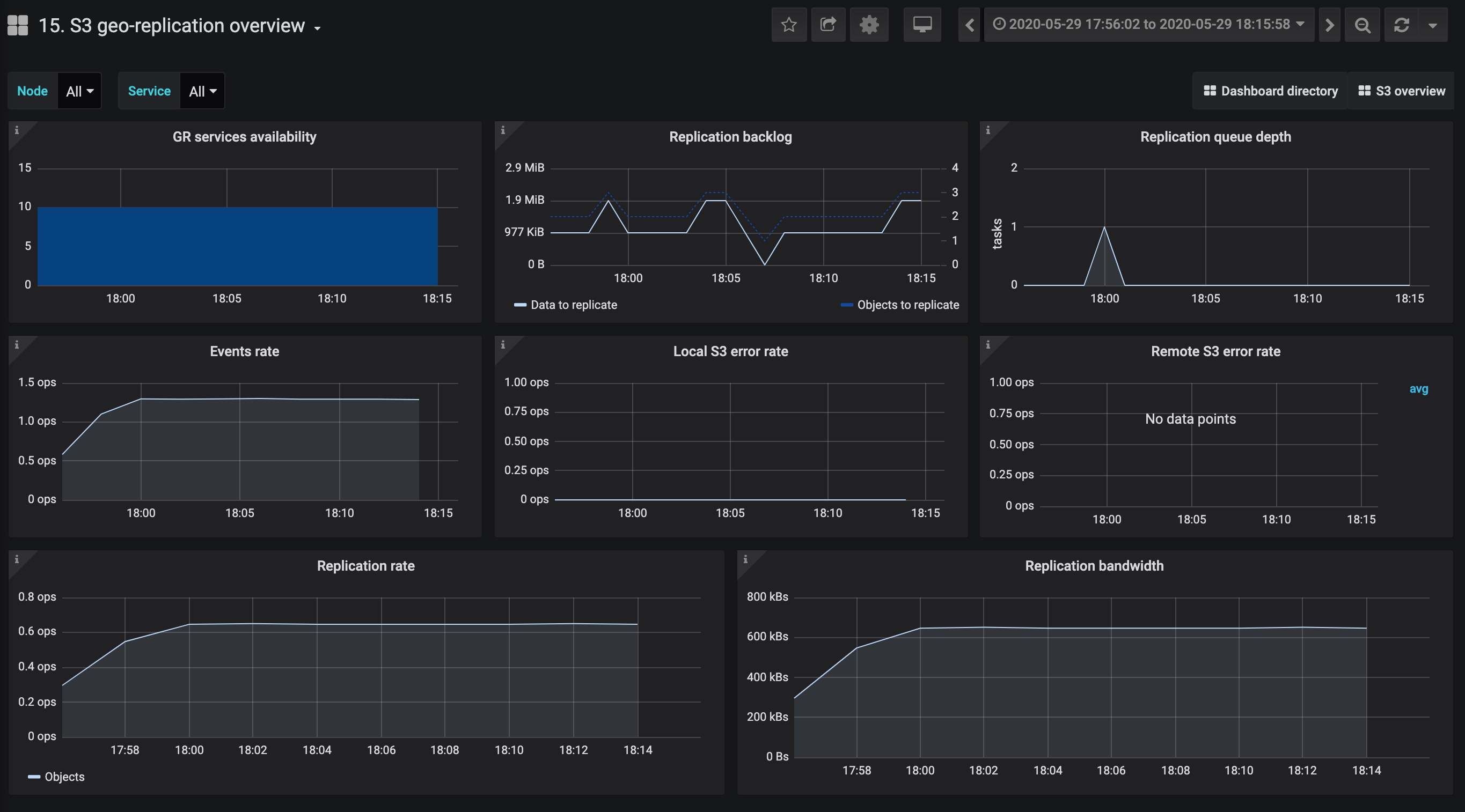
Das Dashboard S3-Überblick zeigt primär die S3-GW-Service Informationen an. Hier können Sie den Objekt-Storage und die S3-Schnittstelle mit folgenden Diagrammen überwachen:
- S3-Gateways-Verfügbarkeit, NS-Services-Verfügbarkeit und OS-Services-Verfügbarkeit. Die Diagramme zeigen Informationen zu den entsprechenden S3 Services an. Die Zeiträume, in denen die Services nicht verfügbar sind, werden rot hervorgehoben.
- GET-Latenz und PUT-Latenz. Die Diagramme zeigen die durchschnittliche Latenz sowie die 95., 99. und maximale Latzenz-Perzentile der S3-GET- und PUT-Anfragen. Dieser Wert wird ab dem Zeitpunkt gemessen, an dem das letzte Byte der Anfrage empfangen wurde, bis zu dem Zeitpunkt, an dem das erste Byte der Antwort gesendet wurde.
- Bandbreite. Das Diagramm zeigt die Gesamtzahl der Lese- oder Schreib-Operationen an, die alle S3-Gateways pro Sekunde durchlaufen.
- Operationsraten. Das Diagramm zeigt die Gesamtzahl der GET-, PUT-, LIST- und DELETE-S3-Operationen pro Sekunde für alle S3-Gateways an.
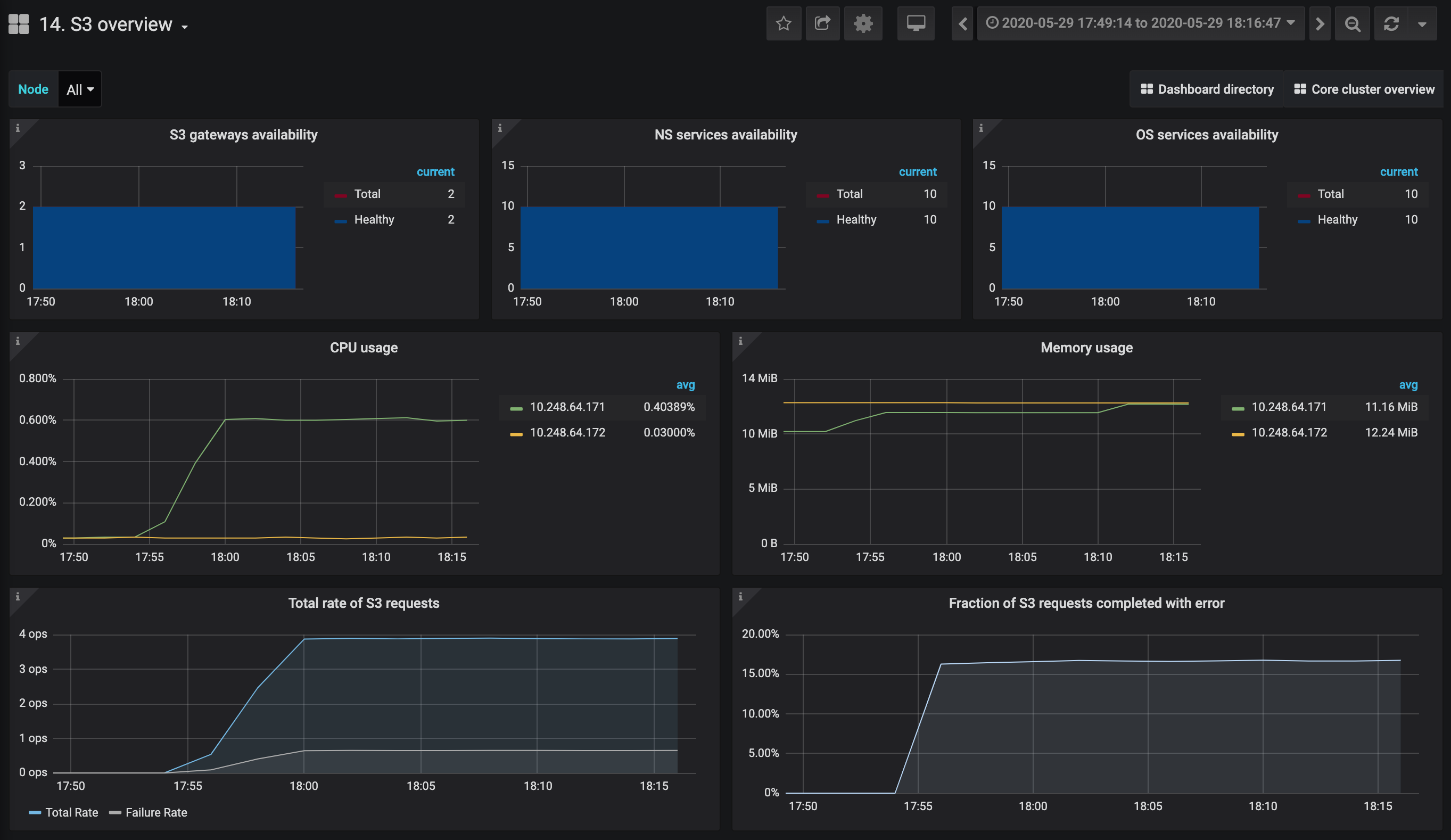
Das Dashboard S3-Georeplikation – Überblick dient zur Überwachung der Daten, die zwischen multiplen geografisch verteilten Datacentern repliziert werden:
- Replikationsrückstand und Replikationswarteschlangentiefe sind hier die wichtigsten Diagramme. Wenn diese Werte stetig wachsen, sinkt die Replikationseffizienz. Das bedeutet dann, dass der Cluster mehr Daten empfängt als sendet.
- Fehlerrate für lokal S3 und Fehlerrrate für Remote-S3 helfen bei der Lokalisierung von Verbindungsproblemen. Eine geringe Anzahl von Fehlern ist möglich, wenn die Cluster mit instabiler Latenz über das Internet repliziert werden.