10.9. Enabling high availability¶
High availability (HA) keeps Acronis Cyber Infrastructure services operational even if the node they are located on fails. In such cases, services from a failed node are relocated to healthy nodes, according to the Raft consensus algorithm. High availability is ensured by:
- Metadata redundancy. For a storage cluster to function, not all but just the majority of MDS servers must be up. By setting up multiple MDS servers in the cluster, you will make sure that if an MDS server fails, other MDS servers will continue controlling the cluster.
- Data redundancy. Copies of each piece of data are stored across different storage nodes, to ensure that the data is available even if some of the storage nodes are inaccessible.
- Monitoring of node health.
To achieve the complete high availability of the storage cluster and its services, we recommend that you do the following:
- Deploy three or more metadata servers. The required number of metadata servers is deployed automatically, based on recommended hardware configurations.
- Enable management node HA. Management node HA must be enabled manually.
- Enable HA for the specific service. High availability for services is enabled by adding the minimum required number of nodes to that service’s cluster.
On top of highly available metadata services and enabled management node HA, Acronis Cyber Infrastructure provides additional high availability for the following services:
- Admin panel. If the management node fails or becomes unreachable over the network, an admin panel instance on another node takes over the panel’s service so that it remains accessible at the same dedicated IP address. The relocation of the service can take several minutes. Admin panel HA is enabled manually along with management node HA (refer to Enabling management node high availability).
- Virtual machines. If a compute node fails or becomes unreachable over the network, virtual machines hosted on it are evacuated to other healthy compute nodes based on their free resources. The compute cluster can survive the failure of only one node. By default, high availability for virtual machines is enabled automatically after creating the compute cluster and can be disabled manually, if required (refer to Configuring virtual machine high availability).
- iSCSI service. If the active path to volumes exported via iSCSI fails (for example, a storage node with active iSCSI targets fails or becomes unreachable over the network), the active path is rerouted via targets located on healthy nodes. Volumes exported via iSCSI remain accessible as long as there is at least one path to them.
- S3 service. If an S3 node fails or becomes unreachable over the network, the name server and object server components hosted on it are automatically balanced and migrated between other S3 nodes. S3 gateways are not automatically migrated; their high availability is based on DNS records. You need to maintain the DNS records manually when adding or removing S3 gateways. High availability for the S3 service is enabled automatically after enabling management node HA and creating an S3 cluster from three or more nodes. The S3 cluster of three nodes may lose one node and remain operational.
- Backup Gateway service. If a node included in the Backup Gateway cluster fails or becomes unreachable over the network, other nodes in the Backup Gateway cluster continue to provide access to the chosen storage backend. Backup gateways are not automatically migrated; their high availability is based on the DNS records. You need to maintain the DNS records manually when adding or removing backup gateways. High availability for the backup gateway is enabled automatically after creating a Backup Gateway cluster from two or more nodes. Access to the storage backend remains until at least one node in the Backup Gateway cluster is healthy.
- NFS shares. If a storage node fails or becomes unreachable over the network, the NFS volumes located on it are migrated between other NFS nodes. High availability for NFS volumes on a storage node is enabled automatically after creating an NFS cluster.
10.9.1. Enabling management node high availability¶
To make your infrastructure more resilient and redundant, you can create a high availability configuration of three nodes.
Management node high availability (HA) and the compute cluster are tightly coupled, so changing nodes in one usually affects the other. Take note of the following:
- Each node in the HA configuration must meet the requirements for the management node, listed in the Hardware requirements. If the compute cluster is to be created, its hardware requirements must be added as well.
- If the HA configuration has been created before the compute cluster, all nodes in it will be added to the compute cluster.
- If the compute cluster has been created before the HA configuration, only nodes in the compute cluster can be added to the HA configuration. For this reason, to add a node to the HA configuration, add it to the compute cluster first.
- If both the HA configuration and compute cluster include the same three nodes, single nodes cannot be removed from the compute cluster. In such a case, the compute cluster can be destroyed completely, but the HA configuration will remain. This is also true vice versa, the HA configuration can be deleted, but the compute cluster will continue working.
Note
The compute cluster must have at least three nodes, to allow self-service users to enable high availability for Kubernetes master nodes.
To enable high availability for the management node and admin panel, do the following:
Make sure that each node is connected to a network with the Admin panel and Internal management traffic types.
On the Settings > Management node screen, open the Management high availability tab.
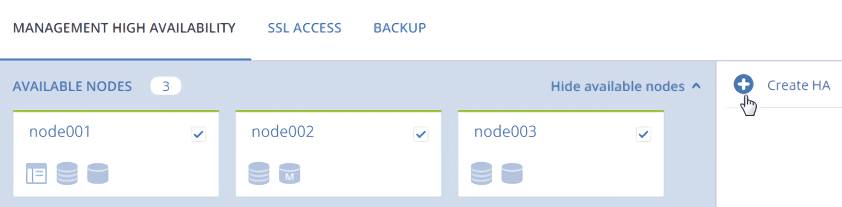
Select three nodes, and then click Create HA. The management node is automatically selected.
On Configure network, verify that the correct network interfaces are selected on each node. Otherwise, click the cogwheel icon for a node and assign networks with the Internal management and Admin panel traffic types to its network interfaces. Click Proceed.
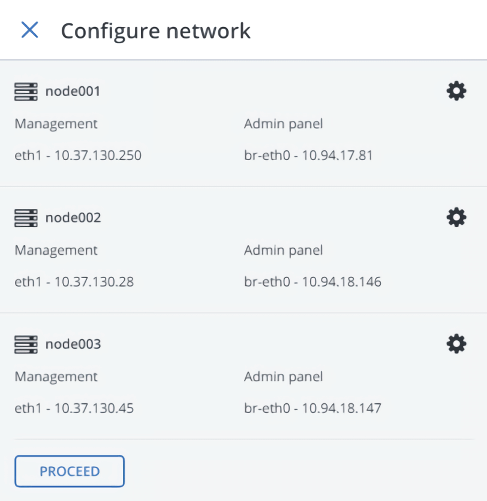
On Configure network, provide one or more unique static IP addresses for the highly available admin panel, compute API endpoint, and interservice messaging. Click Done.

Once the high availability of the management node is enabled, you can log in to the admin panel at the specified static IP address (on the same port 8888).
As the management node HA must include exactly three nodes at all times, removing a node from the HA configuration is not possible without adding another one at the same time. For example, to remove a failed node from the HA configuration, you can replace it with a healthy one. Do the following:
On the Settings > Management node > Management high availability tab, select one or two nodes that you wish to remove from the HA configuration and one or two available nodes that will be added into the HA configuration instead, and then click Replace.
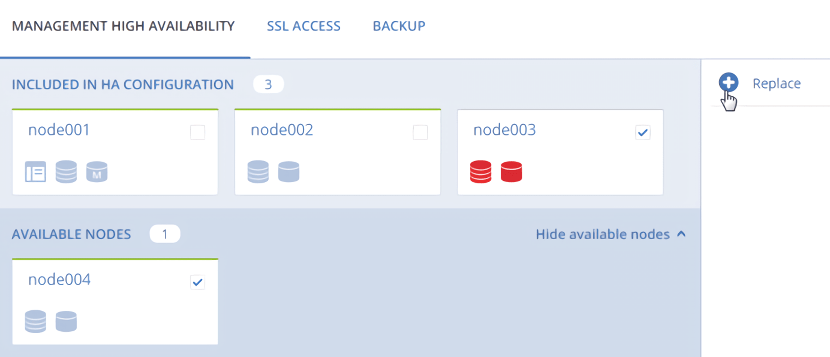
On Configure network, verify that correct network interfaces are selected on each node to be added. Otherwise, click the cogwheel icon for a node and assign networks with the Internal management and Admin panel traffic types to its network interfaces. Click Proceed.
To remove nodes from the HA configuration, click Destroy HA.