3.1. About Object Storage¶
Object storage is a storage architecture that enables managing data as objects (like in a key-value storage) as opposed to files in file systems or blocks in a block storage. Except for the data, each object has metadata that describes it as well as a unique identifier that allows finding the object in the storage. Object storage is optimized for storing billions of objects, in particular for application storage, static web content hosting, online storage services, big data, and backups. All of these uses are enabled by object storage thanks to a combination of very high scalability and data availability and consistency.
Compared to other types of storage, the key difference of object storage is that parts of an object cannot be modified, so if the object changes a new version of it is spawned instead. This approach is extremely important for maintaining data availability and consistency. First of all, changing an object as a whole eliminates the issue of conflicts. That is, the object with the latest timestamp is considered to be the current version and that is it. As a result, objects are always consistent, i.e. their state is relevant and appropriate.
Another feature of object storage is eventual consistency. Eventual consistency does not guarantee that reads are to return the new state after the write has been completed. Readers can observe the old state for an undefined period of time until the write is propagated to all the replicas (copies). This is very important for storage availability as geographically distant data centers may not be able to perform data update synchronously (e.g., due to network issues) and the update itself may also be slow as awaiting acknowledges from all the data replicas over long distances can take hundreds of milliseconds. So eventual consistency helps hide communication latencies on writes at the cost of the probable old state observed by readers. However, many use cases can easily tolerate it.
3.1.1. Object Storage Infrastructure Overview¶
The object storage infrastructure consists of the following entities: object servers (OS), name servers (NS), S3 gateways (GW), and the block-level backend.
These entities run as services on the Acronis Storage nodes. Each service should be deployed on multiple Acronis Storage nodes for high availability.
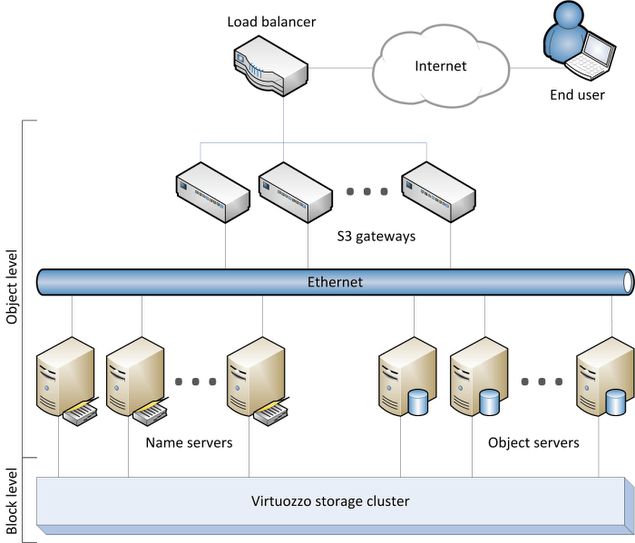
- An object server stores actual object data received from S3 gateway. The data is packed into special containers to achieve high performance. The containers are redundant, you can specify the redundancy mode while configuring object storage. An object server also stores its own data in block storage with built-in high availability.
- A name server stores object metadata received from S3 gateway. Metadata includes object name, size, ACL (access control list), location, owner, and such. Name server (NS) also stores its own data in block storage with built-in high availability.
- An S3 gateway is a data proxy between object storage services and end users. It receives and handles Amazon S3 protocol requests and S3 user authentication and ACL checks. The S3 gateway uses the NGINX web server for external connections and has no data of its own (i.e. is stateless).
- The block-level backend is block storage with high availability of services and data. Since all object storage services run on hosts, no virtual environments (and hence licenses) are required for object storage.
For more information, see Object Storage Components.
3.1.2. Object Storage Overview¶
In terms of S3 object storage, a file is an object. Object servers store each object loaded via the S3 API as a pair of entities:
- Object names and associated object metadata stored on an NS. An object name in the storage is determined based on request parameters and bucket properties in the following way:
- If bucket versioning is disabled, an object name in the storage contains bucket name and object name taken from an S3 request.
- If bucket versioning is enabled, an object name also contains a list of object versions.
- Object data stored on an OS. The directory part of an object name determines an NS to store it while the full object name determines an OS to store the object data.
3.1.2.1. Multipart Uploads¶
A name of a multipart upload is defined by a pattern similar to that of an object name but the object that corresponds to it contains a table instead of file contents. The table contains index numbers of parts and their offsets within the file. This allows to upload parts of a multi-part upload in parallel (recommended for large files). The maximum number of parts is 10,000.
3.1.2.2. Object Storage Interaction with a Storage Cluster¶
An S3 storage cluster requires a working Acronis Storage cluster on each of S3 cluster nodes. Acronis Storage provides content sharing, strong consistency, data availability, reasonable performance for random I/O operations, and high availability for storage services. In storage terms, S3 data is a set of files (see Object Server) that the Acronis Storage filesystem layer (vstorage-mount) does not interpret in any way.
3.1.3. Object Storage Components¶
This section offers more detail on S3 storage components: gateways, object servers, and name servers; and describes S3 management tools and service buckets.
3.1.3.1. Gateway¶
A gateway performs the following functions:
- Receives S3 requests from the web server (via NGINX and FastCGI).
- Parses S3 packets and validates S3 requests (checks fields of a request and XML documents in its body).
- Authenticates S3 users.
- Validates access permissions to buckets and objects using ACL.
- Collects statistics on the number of various requests as well as the amount of the data received and transmitted.
- Determines paths to NS and OS storing the object’s data.
- Inquires names and associated metadata from NS.
- Receives links to objects stored on OSes by requesting the name from NSes.
- Caches metadata and ACL of S3 objects received from NSes as well as the data necessary for user authentication also stored on the NSes.
- Acts as a proxy server when clients write and read object data to and from the OSes. Only the requested data is transferred during read and write operations. For example, if a user requests to read 10MB from a 1TB object, only said 10MB will be read from the OS.
S3 gateway consists of incoming requests parser, type-dependent asynchronous handlers of these requests, and an asynchronous handler of the interrupted requests that require completion (complex operations such as bucket creation or removal). Gateway does not store its state data in the long-term memory. Instead, it stores all the data needed for S3 storage in the object storage itself (on NS and OS).
3.1.3.2. Name Server¶
A name server performs the following functions:
- Stores object names and metadata.
- Provides the API for pasting, deleting, listing object names and changing object metadata.
Name server consists of data (i.e. object metadata), object change log, an asynchronous garbage collector, and asynchronous handlers of incoming requests from different system components.
The data is stored in a B-tree where to each object’s name corresponds that object’s metadata structure. S3 object metadata consists of three parts: information on object, user-defined headers (optional), and ACL for the object. Files are stored in the corresponding directory on base shared storage (i.e. Acronis Storage).
Name server is responsible for a subset of S3 cluster object namespace. Each NS instance is a userspace process that works in parallel with other processes and can utilize up to one CPU core. The optimal number of name servers are 4-10 per node. We recommend to start with creating 10 instances per node during cluster creation to simplify scalability later. If your node has CPU cores that are not utilized by other storage services, you can create more NSes to utilize these CPU cores.
3.1.3.3. Object Server¶
An object server performs the following functions:
- Stores object data in pools (data containers).
- Provides an API for creating, reading (including partial reads), writing to, and deleting objects.
Object server consists of the following:
- information on object’s blocks stored on this OS,
- containers that store object data,
- asynchronous garbage collector that frees container sections after object delete operations.
Object data blocks are stored in pools. The storage uses 12 pools with blocks the size of the power of 2, ranging from 4 kilobytes to 8 megabytes. A pool is a regular file on block storage made of fixed-size blocks (regions). In other words, each pool is an extremely large file designed to hold objects of specific size: the first pool is for 4KB objects, the second pool is for 8KB objects, etc.
Each pool consists of a block with system information, and fixed-size data regions. Each region contains has a free/dirty bit mask. The region’s data is stored in the same file with an object’s B-tree. It provides atomicity during the block’s allocation and deallocation. Every block in the region contains a header and object’s data. The header stores the ID of an object to which the data belong. The ID is required for a pool-level defragmentation algorithm that does not have an access to the object’s B-tree. A pool to store an object is chosen depending on object size.
For example, a 30KB object will be placed into the pool for 32KB objects and will occupy a single 32KB object. A 129KB object will be split into one 128KB part and one 1KB part. The former will be placed in the pool for 128KB objects while the latter will go to the pool for 4KB objects. The overhead may seem significant in case of small objects as even a 1-byte object will occupy a 4KB block. In addition, about 4KB of metadata per object will be stored on NS. However, this approach allows achieving the maximum performance, eliminates free space fragmentation, and offers guaranteed object insert performance. Moreover, the larger the object, the less noticeable the overhead. Finally, when an object is deleted, its pool block is marked free and can be used to store new objects.
Multi-part objects are stored as parts (each part being itself an object) that may be stored on different object servers.
3.1.3.4. S3 Management Tools¶
Object storage has two tools:
ostorfor configuring storage components, ands3-ostor-adminfor user management, an application that allows to create, edit, and delete S3 user accounts as well as manage account access keys (create and delete paired S3 access key IDs and S3 secret access keys).
3.1.3.5. Service Bucket¶
The service bucket stores service and temporary information necessary for the S3 storage. This bucket is only accessible by the S3 admin (while the system admin would need access keys created with the s3-ostor-admin tool). The information corresponds to the following names in the object storage:
- Names with a
/u/prefix. Correspond to user data (user identifier, e-mail, access key ID, and secret access key). - Names with an
/m/prefix. Correspond to temporary information on current multipart uploads and their parts. - Names with a
/tmp/prefix. Correspond to information on operations that consist of several atomic alterations of objects in the storage. These names are necessary in case the operation fails.
3.1.4. Data Interchange¶
In object storage, every service has a 64-bit unique identifier. At the same time, every object has a unique name. The directory part of an object’s name determines a name server to store it, and the full object’s name—an object server to store the object’s data. Name and object server lists are stored in a vstorage cluster directory intended for object storage data and available to anyone with a cluster access. This directory includes subdirectories that correspond to services hosted on name and object servers. The names of subdirectories match hexadecimal representations of the service’s ID. In each service’s subdirectory, there is a file containing an ID of a host that runs the service. Thus, with the help of a gateway, a system component with a cluster access can discover an ID of a service, detect its host, and send a request to it.
S3 gateway handles data interchange with the following components:
- Clients via a web server. Gateway receives S3 requests from users and responds to them.
- Name servers. Gateway creates, deletes, changes the names that correspond to S3 buckets or objects, checks their existence, and requests name sets of bucket lists.
- Object servers in the storage. Gateway sends data altering requests to object and name servers.
3.1.4.1. Data Caching¶
To enable efficient data use in object storage, all gateways, name servers, and object servers cache the data they store. Name and object servers both cache B-trees.
Gateways store and cache the following data received from name services:
- Lists of paired user IDs and e-mails.
- Data necessary for user authentication: access key IDs and secret access keys. For more information on their semantics, consult the Amazon S3 documentation.
- Metadata and bucket’s ACLs. The metadata contains its epoch, current version identifier and transmits it to NS to check if the gateway has the latest version of the metadata.
3.1.5. Operations on Objects¶
This section familiarizes you with operations S3 storage processes: operations requests; create, read, and delete operations.
3.1.5.1. Operation Requests¶
To create, delete, read an object or alter its data, S3 object storage must first request one if these operations and then perform it. The overall process of requesting and performing an operation consists of the following:
- Requesting user authentication data. It will be stored on a name server in a specific format (see Service Buckets). To receive data (identifier, e-mail, access keys), a request with a lookup operation code is sent to an appropriate name server.
- Authenticating the user.
- Requesting bucket’s and object’s metadata. To receive it, another request with a lookup operation code is sent to the name server that stores names of objects and buckets.
- Checking user’s access permissions to buckets and objects.
- Performing the requested object operation: creating, editing or reading data or deleting the object.
3.1.5.2. Create Operation¶
To create an object, gateway sends the following requests:
- Request with a guard operation code to a name server. It creates a guard with a timer which will check after a fixed time period if an object with the data was indeed created. If it was not, the create operation will fail and the guard will request the object server to delete the object’s data if some were written. After that the guard is deleted.
- Request with a create operation code to an object server followed by fixed-size messages containing the object’s data. The last message includes an end-of-data flag.
- Another request with a create operation code to the name server. The server checks if the corresponding guard exists and, if it does not, the operation fails. Otherwise, the server creates a name and sends a confirmation of successful creation to the gateway.
3.1.5.3. Read Operation¶
To fulfill an S3 read request, gateway determines an appropriate name server’s identifier based on the name of a directory and corresponding object server’s identifier based on the object’s full name. To perform a read operation, gateway sends the following requests:
- Request with a read operation code to an appropriate name server. A response to it contains a link to an object.
- Request to an appropriate object server with a read operation code and a link to an object received from the name server.
To fulfill the request, object server transmits fixed-size messages with the object’s data to the gateway. The last message contains an end-of-data flag.
3.1.5.4. Delete Operation¶
To delete an object (and its name) from the storage, gateway determines a name server’s identifier based on the directory’s part of a name and sends a request with a delete operation code to the server. In turn, the name server removes the name from its structures and sends the response. After some time, the garbage collector removes the corresponding object from the storage.