2.2. Storage-Richtlinien verstehen¶
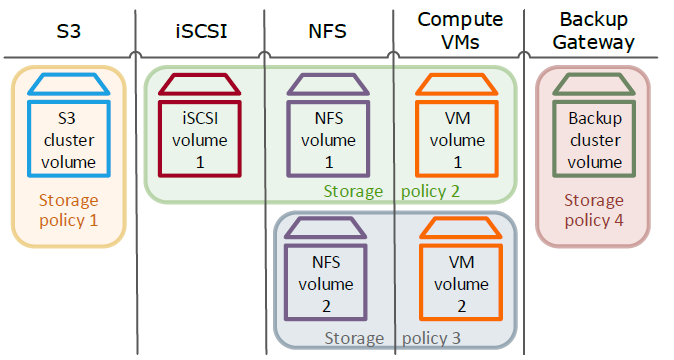
Acronis Cyber Infrastructure kann für folgende Szenarien verwendet werden: als iSCSI-Block-Storage, als NFS-Datei-Storage, als S3-Objekt-Storage, als Backup Storage (zum Speichern von Backups, die mit den Acronis Cyber Backup-Lösungen erstellt wurden). Sie können außerdem den im Produkt integrierten Hypervisor verwenden, um virtuelle Compute-Maschinen (Compute-VMs) zu erstellen. In all diesen Szenarien ist die gemeinsame Dateneinheit ein Volume. Für den Compute-Service ist ein Volume ein virtuelles Laufwerk, das an eine VM angeschlossen werden kann. Bei iSCSI, S3, das Backup Gateway und NFS ist ein Volume die Dateneinheit, die zum Exportieren von Speicherplatz verwendet wird. In all diesen Fällen müssen Sie beim Erstellen eines Volumes dessen Redundanzmodus, Ebene und Fehlerdomäne definieren. Diese Parameter ergeben zusammen eine Storage-Richtlinie, die definiert, wie redundant ein Volume sein muss und wo es gespeichert sein muss.
Redundanz bedeutet, dass die Daten über verschiedene Storage-Knoten verteilt gespeichert werden und daher selbst dann hochverfügbar bleiben, wenn einige dieser Knoten ausfallen sollten. Wenn ein Storage-Knoten nicht verfügbar ist, werden die auf ihm gespeicherten Datenkopien durch neue ersetzt, die über die intakten Storage-Knoten verteilt werden. Wenn der Storage-Knoten nach einem solchen Ausfall wieder in Betrieb geht, werden die auf ihm gespeicherten Daten, die jetzt veraltet sind/sein können, durch die Datenkopien der anderen Storage-Knoten aktualisiert.
Mit der Replikation zerlegt Acronis Cyber Infrastructure ein Volume in Datenblöcke mit fester Größe, die auch Daten-Chuncks genannt werden. Jeder Chunk wird so oft repliziert, wie in es in der Storage-Richtlinie festgelegt ist. Die Replikate werden auf verschiedenen Storage-Knoten gespeichert, wenn die Fehlerdomäne als ‚Host‘ festgelegt ist, sodass jeder Knoten nur ein Replikat eines bestimmten Chunks besitzt.
Beim Lösch-Codierungsverfahren (oder nur Codierung) werden die eingehenden Datenströme in Fragmente einer bestimmten Größe aufgeteilt. Anschließend wird nicht jedes Fragment selbst kopiert, sondern eine bestimmte Anzahl (M) solcher Fragmente gruppiert und eine bestimmte Anzahl (N) von Paritätsstücken aus Redundanzgründen erstellt. Alle Teilstücke werden dann auf M+N Storage-Knoten verteilt (aus allen verfügbaren Knoten ausgewählt). Die Daten können so den Ausfall von N Storage-Knoten (egal welchen) überstehen, ohne dass es zu Datenverlusten kommt. Die Werte von M und N werden im Namen des jeweiligen Lösch-Codierungs-Redundanzmodus angegeben. Beim 5+2-Modus beispielsweise werden die einkommenden Daten in 5 Fragmente aufgeteilt – und dann 2 weitere Paritätsteile (gleicher Größe) aus Redundanzgründen hinzugefügt. Ausführliche Informationen zu Redundanz, Daten-Overhead, Anzahl der Knoten und erforderlichem Raw-Speicherplatz finden Sie in der Anleitung für Administratoren .
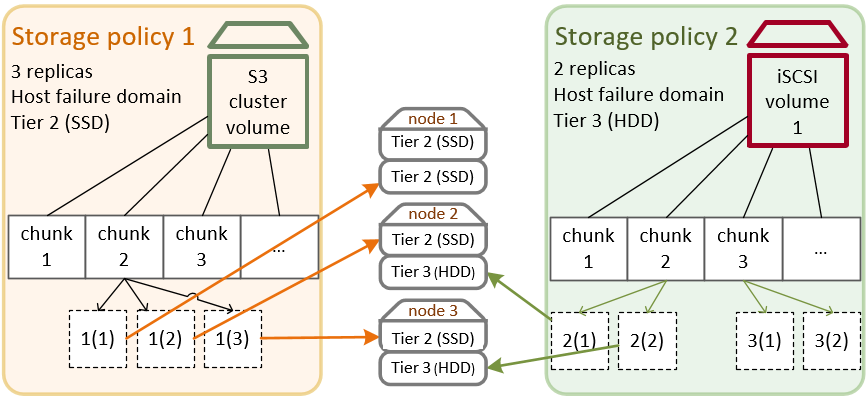
Um ein besseres Verständnis für eine Storage-Richtlinien zu erhalten, werfen wir mit einem Beispielszenario einen Blick auf ihre Hauptkomponenten (Storage-Ebenen, Fehlerdomänen und Redundanz). Angenommen, Sie haben drei Knoten mit einer bestimmten Anzahl von Storage-Laufwerken: schnelle SSDs und HDDs mit hoher Kapazität. Knoten 1 hat nur SSDs; Knoten 2 und 3 haben sowohl SSDs als auch HDDs. Sie möchten Speicherplatz über iSCSI und S3 exportieren, daher müssen Sie für jeden Workload eine geeignete Storage-Richtlinie definieren.
- Der erste Parameter, die Ebene, definiert eine Gruppe von Laufwerken, die nach bestimmten Kriterien (in der Regel nach dem Laufwerkstyp) vereint und auf einen bestimmten Storage-Workload zugeschnitten sind. Für dieses Beispielszenario können Sie Ihre SSD-Laufwerke in Ebene 2 und die HDD-Laufwerke in Ebene 3 gruppieren. Sie können ein Laufwerk einer solchen Ebene zuweisen, wenn Sie einen Storage-Cluster erstellen oder dem Storage-Cluster einen Knoten hinzufügen (siehe den Abschnitt ‚Den Storage-Cluster erstellen‘). Beachten Sie, dass nur die Knoten 2 und 3 über HDDs verfügen und für Ebene 3 verwendet werden. Die SSDs des ersten Knotens können nicht für Ebene 3 verwendet werden.
- Der zweite Parameter, die Fehlerdomäne, definiert einen Bereich, innerhalb dessen eine Zusammenstellung von Storage-Services in einer korrelierten Weise ausfallen können. Die Standard-Fehlerdomäne ist ‚Host‘. Jeder Datenblock (Chunk) wird auf verschiedene Storage-Knoten kopiert, mit je nur eine Kopie pro Knoten. Sollte ein Knoten ausfallen, sind die Daten weiterhin über die intakten Knoten zugänglich. Ein Laufwerk kann auch eine Fehlerdomäne sein, obwohl dies nur bei 1-Knoten-Clustern relevant ist. Weil Sie in unserem Szenario drei Knoten haben, empfehlen wir, die Fehlerdomäne ‚Host‘ zu wählen.
- Der dritte Parameter, die Redundanz, sollte so konfiguriert werden, dass er zu den Laufwerken und Ebenen passt. In unserem Evaluierungsbeispiel haben Sie drei Knoten: alle haben SSDs auf Ebene 2. Wenn Sie in Ihrer Storage-Richtlinie also die Ebene 2 auswählen, können Sie die drei Knoten für 1, 2 oder auch 3 Replikate verwenden. Aber nur zwei Ihrer Knoten haben HDDs auf Ebene 3. Wenn Sie in Ihrer Storage-Richtlinie also die Ebene 3 auswählen, können Sie nur 1 oder 2 Replikate auf den beiden Knoten speichern. In beiden Fällen könnten Sie auch eine Codierung verwenden. Für unsere Evaluierung bleiben wir aber bei der Replikation: 3 Replikate für SSDs und 2 Replikate für HDDs.
Zusammengefasst ergeben sich daraus die folgenden Storage-Richtlinien: