2.6. Performing Node Maintenance¶
Whenever you need to perform service operations on a cluster node, place it in the maintenance mode. When you do so, the node stops allocating new chunks of storage data, but continues to handle I/O operations for the core storage services such as MDS, CS, and cache. Other node’s services (compute, Backup Gateway, iSCSI, S3, and NFS) can either be relocated or left as is during maintenance. Once the node is in the maintenance mode, you can shut it down and perform service operations on it. Once you are done, power on the node and return it to operation in the admin panel.
Important
It is recommended to have five MDS services in the storage cluster. In this case, when a node running MDS service is shut down during maintenance, the cluster can survive failure of another node.
Before placing a node in the maintenance mode, do the following:
- If the node hosts virtual machines, they will be relocated. Make sure that other compute nodes have enough resources to accommodate these VMs.
- If the node hosts iSCSI targets, make sure that iSCSI initiators are configured to use multiple IP addresses from the same target group.
- If the node runs an S3 gateway, remove its IP addresses from DNS records of S3 access points. Otherwise, some of S3 clients may experience connection timeouts.
To place a node in the maintenance mode, do the following:
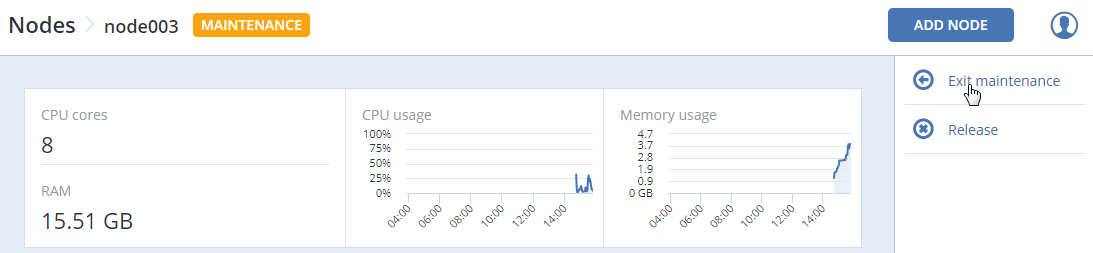
On the INFRASTRUCTURE > Nodes screen, click the desired node.
On the node overview screen, click Enter maintenance.
In the Enter maintenance window, choose to Evacuate or Ignore the following workloads during maintenance:
- Block storage. iSCSI target groups are highly available, with multiple targets running on different nodes. When the node enters maintenance, the target it hosts is stopped and the preferred path is moved to another node in the target group within 60 seconds. Thus the service is not interrupted during maintenance.
- Block storage (version 2.4 or earlier). Old iSCSI targets created in version 2.4 or earlier will be evacuated from the node and migrated back after maintenance. To avoid this, it is recommended to convert old targets to new target groups as described in Managing Legacy iSCSI Targets.
Compute. Evacuating virtual machines from the node means migrating them live one by one to other compute nodes. If you choose to ignore them, they will continue running until you reboot or shut down the node. In this case, they will be stopped and shelved, resulting in downtime. They also will not be started automatically once the node is up again.
Important
Suspended VMs cannot be evacuated from the node and will be ignored.
S3. You can evacuate S3 services from this node to other nodes in the S3 cluster or ignore them. In the latter case, they will continue running until you reboot or shut down the node, resulting in downtime. They will be started automatically once the node is up again.
NFS. You can evacuate NFS services from this node to other nodes in the NFS cluster or ignore them. In the latter case, they will continue running until you reboot or shut down the node, resulting in downtime. They will be started automatically once the node is up again.
ABGW. This service is highly available, with multiple instances spread across different nodes. Placing this node in maintenance mode will stop one of the instances but the others will continue working, so the service will not be interrupted.
Cluster self-healing is automatic restoration of storage cluster data that becomes unavailable when a storage node (or a disk) goes offline. If this happens during maintenance, self-healing is delayed (for 30 minutes by default) to save cluster resources. If the node goes back online before the delay ends, self-healing is not necessary.
You can manually configure the replication timeout by setting the
mds.wd.offline_tout_mntparameter, in milliseconds, with thevstorage -c <cluster_name> set-configcommand.In addition, any non-redundant chunks of data on the node will become unavailable if the node goes offline. They will, however, be moved to other storage nodes if you check the box Relocate non-redundant data. They may also be temporarily moved to another tier if the current one is full.
In general, all CSes on the node will continue serving data even in the maintenance mode unless the node goes offline. They will not, however, be used to allocate new data, so placing the node in maintenance may reduce the free space in the storage cluster.
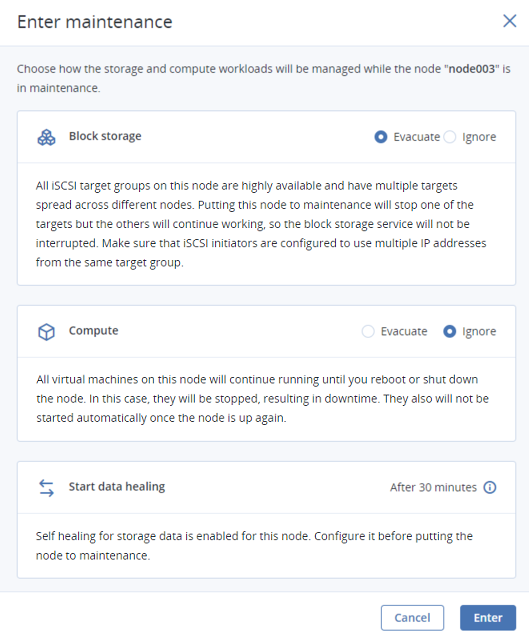
Click Enter.
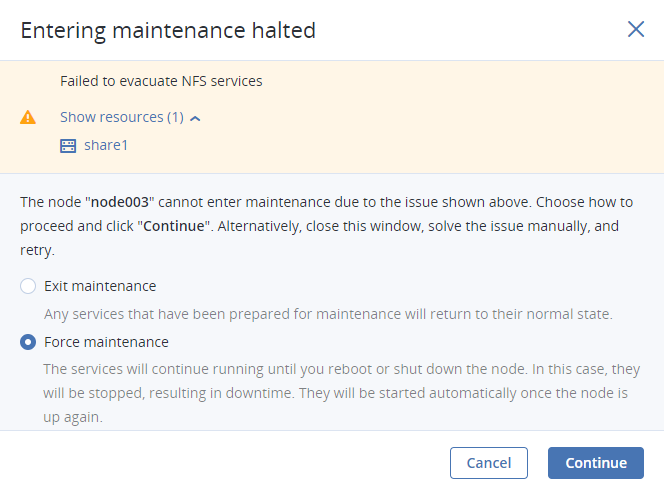
If a service cannot be evacuated from the node for some reason, entering maintenance will be halted. You will need to decide on how to proceed: exit maintenance so that all services on the node are returned to their normal state; or force maintenance so that the services that could not be evacuated are stopped during node reboot or shutdown. On the node overview screen, click Enter maintenance, choose the desired action, and click Continue.
Nodes in maintenance can be returned to operation or released.
To return a node to operation, click Exit maintenance on its overview screen.