3.1. Den kompletten Cluster überwachen¶
Die Gesamtstatistiken für den Storage-Cluster sind auf der Anzeige ÜBERWACHUNG –> Dashboard verfügbar. Achten Sie auf den Storage-Cluster-Status, der einen der folgenden Zustände annehmen kann:
- FEHLERFREI
- Alle Cluster-Komponenten sind aktiv und funktionieren normal.
- NICHT VERFÜGBAR
- Es gibt nicht genügend Informationen über den Cluster-Zustand (z.B. weil derzeit nicht auf den Cluster zugegriffen werden kann).
- HERUNTERGESTUFT
- Einige der Cluster-Komponenten sind nicht aktiv oder nicht verfügbar. Der Cluster versucht, sich selbst zu reparieren, die Datenreplikation ist geplant oder wird gerade ausgeführt.
- FEHLER
- Der Cluster hat zu viele inaktive Services; die automatische Replikation wurde deaktiviert. Wenn der Cluster diesen Zustand annimmt, sollten Sie versuchen, die Probleme des Knotens zu beheben oder das Support-Team kontaktieren.
Klicken Sie auf Vollbildmodus, wenn Sie die Storage-Cluster-Statistiken in voller Größe auf dem ganzen Bildschirm sehen wollen. Sie können den Vollbildmodus durch Drücken der Esc-Taste beenden oder indem Sie auf Vollbildmodus beenden klicken.
Für eine erweiterte Überwachung können Sie auf Grafana Dashboard klicken. Es wird eine separate Webbrowser-Registerkarte mit vorkonfigurierten Grafana Dashboards geöffnet. Dort können Sie vorhandene Dashboards verwalten, neue erstellen, diese zwischen Benutzern teilen, Alarmmeldungen konfigurieren usw. Die Dashboards verwenden die Prometheus-Datenquelle. Deren Metriken werden 7 Tage lang gespeichert. Wenn Sie diese Aufbewahrungsdauer verlängern wollen, können Sie diese manuell konfigurieren, wie hier beschrieben: Configuring Retention Policy for Prometheus Metrics. Weitere Informationen finden Sie in der Grafana-Dokumentation.
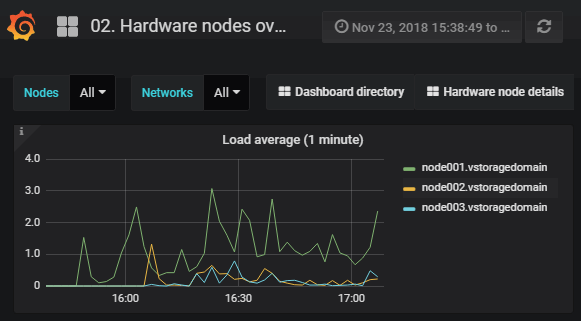
Das Standardzeitintervall für die Diagramme beträgt 12 Stunden. Wenn Sie in ein bestimmtes Zeitintervall zoomen wollen, wählen Sie den internen Bereich mit der Maus aus. Wenn Sie den Zoom zurücksetzen wollen, klicken Sie doppelt auf ein Diagramm.
3.1.1. I/O-Aktivitätsdiagramme¶
Die Diagramme Lesen und Schreiben verdeutlichen den Verlauf der Cluster-I/O-Aktivität über die Geschwindigkeit der I/O-Operationen (je Lesen und Schreiben, in Megabyte pro Sekunde) und deren Anzahl (IOPS). Beispiel:
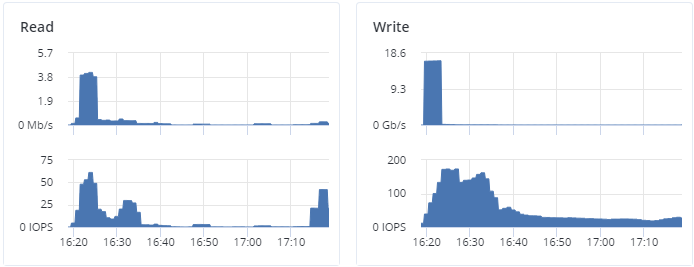
3.1.2. Das Diagramm ‚Services‘¶
Mit dem Diagramm Services können Sie zwei Arten von Services überwachen:
- Metadaten-Services (MDS). Die Anzahl aller Laufwerke mit der Metadaten-Rolle. Stellen Sie sicher, dass immer mindestens drei MDS gleichzeitig ausgeführt werden.
- Chunk-Services (CS). Die Anzahl aller Laufwerke mit der Storage-Rolle.
Eine typische Statistik kann so aussehen:
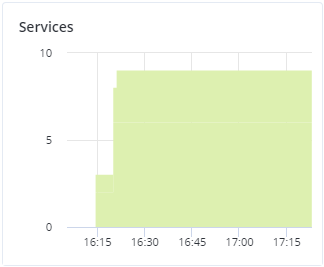
Wenn einige der Services nicht die ganze Zeit im Zustand ‚fehlerfrei‘ waren, werden die betreffenden Zeiträume im Diagramm rot hervorgehoben.
3.1.3. Das Diagramme ‚Blöcke (Chunks)‘¶
Sie können die Stadien aller Chunks im Cluster über das Diagramm Blöcke (Chunks) überwachen. Die Chunks können sich in einem der folgenden Stadien befinden:
- Fehlerfrei
- Anzahl und Prozentsatz aller Chunks, die genügend aktive Replikate haben. Der normale Zustand eines Chunks.
- Offline
Anzahl und Prozentsatz aller Chunks, von denen alle Replikate offline sind. Solche Chunks sind für den Cluster absolut unzugänglich und es können keine Replikations-, Lese- oder Schreib-Operationen mit ihnen durchgeführt werden. Alle Anfragen an einen Offline-Chunk werden eingefroren, bis ein CS, der Replikate dieses Chunks speichert, online geht.
Sie sollten Chunk-Server, die offline sind, möglichst schnell wieder online bringen, um Datenverluste zu vermeiden.
- Blockiert
Anzahl und Prozentsatz aller Chunks, die weniger aktive Replikate haben, als die festgelegte Mindestmenge. Schreibanforderungen an/zu einem blockierten Chunk werden eingefroren, bis er wenigstens über die festgelegte Mindestmenge an Replikaten verfügt. Leseanforderungen an blockierte Chunks sind aber erlaubt, da sie ja einige aktive Replikate haben. Blockierte Chunks haben eine höhere Replikationspriorität als heruntergestufte Chunks.
Blockierte Chunks im Cluster erhöhen das Risiko von Datenverlusten. Verschieben Sie daher jede Wartung an aktiven Cluster-Knoten und bringen Sie Offline-Chunk-Server so schnell wie möglich wieder online.
- Heruntergestuft
- Anzahl und Prozentsatz aller Chunks, deren aktive Replikate wenige sind, aber nicht unter der festgelegten Mindestmenge liegen. Mit solchen Chunks können Lese- und Schreib-Operationen durchgeführt werden. In letzterem Fall erhält ein herabgestufter Chunk jedoch den Status ‚urgent‘ (dringend).
Fehlerfreie Chunks werden auf der Skala in grün, Offline-Chunks in rot, blockierte in gelb und heruntergestufte in grau angezeigt. Beispiel:
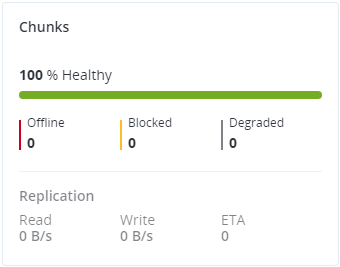
Im Bereich Replikation werden Informationen über die Replikationsaktivität im Cluster angezeigt.
3.1.4. Das Diagramm ‚Physischer Speicherplatz‘¶
Das Diagramm Physischer Speicherplatz zeigt die aktuelle Belegung des physischen Speicherplatzes an – und zwar für den kompletten Storage-Cluster und jede einzelne Storage-Ebene. Zum belegten Speicherplatz gehören der Speicherplatz, der von allen Daten-Chunks und deren Replikaten belegt wird, sowie der Speicherplatz, der von allen anderen Daten belegt wird.
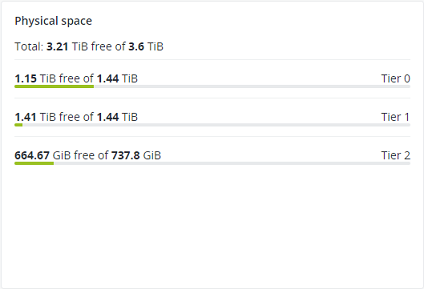
3.1.4.1. Den physischen Speicherplatz verstehen¶
Der gesamte physische Speicherplatz entspricht der Summe des gesamten Speicherplatzes auf allen Storage-Laufwerken und auf derselben Storage-Ebene. Der belegte physische Speicherplatz entspricht der Summe aller Benutzerdaten auf den Storage-Laufwerken derselben Storage-Ebene – unter Berücksichtigung des Redundanzmodus. Der freie Speicherplatz entspricht dem gesamte physischen Speicherplatz minus dem belegten physischen Speicherplatz.
Betrachten wir folgendes Beispiel, um besser zu verstehen, wie der physische Speicherplatz berechnet wird:
| Belegt/Gesamt (Frei), GiB | |||
|---|---|---|---|
Ebene 0, 3+2 Codierung (67% Overhead) |
Ebene 1, 2 Replikate (100% Overhead) |
Ebene 2, ohne Redundanz | |
| Knoten 1 | 334/1024 (690) | 134/512 (378) | 50/256 (206) |
| Knoten 2 | 334/1024 (690) | 133/512 (379) | 50/256 (206) |
| Knoten 3 | 334/1024 (690) | 133/512 (379) | |
| Knoten 4 | 334/1024 (690) | ||
| Knoten 5 | 334/1024 (690) | ||
| Berichtete Zusammenfassung: | 1670/5120 (3450) | 400/1536 (1136) | 100/512 (412) |
Der Cluster verfügt über zehn Laufwerk, denen die Rolle ‚Storage‘ zugewiesen wurde: fünf 1024-GiB-Laufwerke sind der Ebene 0 zugewiesen, drei 512-GiB-Laufwerke der Ebene 1 und zwei 256-GiB-Laufwerke der Ebene 2. Auf den Laufwerken sind keine weiteren Daten (wie z.B. Systemdateien). Ebene 0 speichert 1000 GiB an Benutzerdaten im 3+2 Codierungsmodus. Ebene 1 speichert 200 GiB an Benutzerdaten im 2-Replikate-Modus. Ebene 2 speichert 100 GB an Benutzerdaten ohne Redundanz.
Egal welcher Redundanzmodus verwendet wird: der Cluster versucht, die Daten-Chunks gleichmäßig über alle Laufwerke der gleichen Ebene zu verteilen.
In diesem Beispiel wird der physische Speicherplatz auf jeder Ebene wie folgt berichtet:
- Auf Ebene 0 beträgt der gesamte Speicherplatz 5120 GiB, der belegte Speicherplatz 1670 GiB und der freie Speicherplatz 3450 GiB;
- Auf Ebene 1 beträgt der gesamte Speicherplatz 1536 GiB, der belegte Speicherplatz 400 GiB und der freie Speicherplatz 1136 GiB;
- Auf Ebene 2 beträgt der gesamte Speicherplatz 512 GiB, der belegte Speicherplatz 100 GiB und der freie Speicherplatz 456 GiB.
3.1.5. Das Diagramm ‚Logischer Speicherplatz‘¶
Das Diagramm Logischer Speicherplatz zeigt den gesamten Speicherplatz an, der verschiedenen Services zur Speicherung von Benutzerdaten zugewiesen wurde. Das schließt den Speicherplatz ein, der ausschließlich von Benutzerdaten belegt wird. Replikate und Metadaten für die Lösch-Codierung werden nicht berücksichtigt.
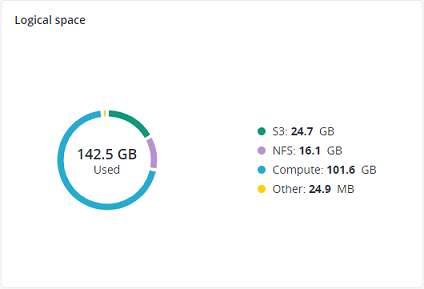
3.1.5.1. Den logischen Speicherplatz verstehen¶
Wenn Sie die Speicherplatz-Informationen im Cluster überwachen, sollten Sie beachten, dass der logische Speicherplatz diejenige Menge an freiem Speicherplatz angibt, der zur Speicherung von Benutzerdaten – also Daten-Chunks und all ihre Replikate – verwendet werden kann. Wenn dieser Speicherplatz verbraucht ist, können keine Daten mehr zum Cluster geschrieben werden.
Um besser zu verstehen, wie der logische Speicherplatz berechnet wird, betrachten wir folgendes Beispiel:
- Der Cluster verfügt über drei Laufwerk, denen die Rolle ‚Storage‘ zugewiesen wurde. Das erste Laufwerk hat 200 GB Speicherplatz, das zweite 500 GB und das dritte 1 TB.
- Wenn der Redundanzmodus auf drei Replikate eingestellt ist, muss jeder Daten-Chunk in Form von drei Replikaten auf drei verschiedenen Laufwerken mit der Rolle ‚Storage‘ gespeichert werden.
In diesem Beispiel beträgt der verfügbare logische Speicherplatz 200 GB – was der Kapazität des kleinsten Laufwerkes mit der Rolle ‚Storage‘ entspricht. Dies ist darin begründet, dass jedes Replikat auf einem anderen Laufwerk gespeichert werden muss. Sobald also dem kleinsten Laufwerk (d.h. hier 200 GB) der Speicherplatz ausgeht, können keine neuen Chunk-Replikate mehr erstellt werden – es sei denn, es wird ein neues Laufwerk mit der Rolle ‚Storage‘ hinzugefügt oder der Redundanzmodus wird auf zwei Replikate geändert.
Beim Redundanzmodus ‚zwei Replikate‘ würde der verfügbare logische Speicherplatz dann 700 GB betragen, da die beiden kleinsten Laufwerke zusammen 700 GB Daten aufnehmen können.