Über den Storage-Cluster
Der Storage-Cluster ermöglicht eine höchst effiziente Nutzung der Hardware mit Lösch-Codierung, integriertem SSD-Caching, automatischem Load Balancer und integrierter RDMA/InfiniBand-Unterstützung. Der Cluster-Speicherplatz kann für folgende Einsatzzwecke verwendet werden:
- iSCSI Block-Storage (für „Hot Data“ und virtuelle Maschinen)
- S3-Objekt-Storage (per Acronis Notary-Blockchain geschützt und mit Georeplikation zwischen den Datacentern)
- Datei-Storage (NFS)
Darüber hinaus ist Acronis Cyber Infrastructure in die Acronis Cyber Protection-Lösungen integriert, um Backups im Cluster speichern oder an Cloud-Services (z.B. Google Cloud, Microsoft Azure, AWS S3) senden oder per NFS-Protokoll auf NAS-Systemen speichern zu können. Die Georeplikation ist für Backup Gateways verfügbar, die auf verschiedenen Storage-Backends eingerichtet sind: einem lokalen Storage-Cluster, einer NFS-Freigabe oder Public Cloud.
Die Datenspeicherungsrichtlinien können an verschiedene Anwendungsfälle angepasst werden: Jedes Daten-Volume kann einen spezifischen Redundanzmodus, eine bestimmte Storage-Ebene sowie Fehlerdomäne haben. Darüber hinaus können die Daten nach dem AES-256-Standard verschlüsselt werden.
Storage-Cluster-Architektur
Die grundlegende Komponente von Acronis Cyber Infrastructure ist ein Storage-Cluster – eine Gruppe von physischen Servern, die über das Netzwerk miteinander verbunden sind. Der Core Storage besteht aus Server-Laufwerken, denen eine oder mehrere Rollen zugewiesen werden. Normalerweise führt jeder Server im Cluster Core Storage-Services aus, die folgenden Laufwerksrollen entsprechen:
-
 Metadaten
Metadaten
Metadaten-Knoten führen Metadaten-Services (MDS) aus, speichern Cluster-Metadaten und kontrollieren, wie Benutzerdateien in Form von Chunks aufgeteilt werden und wo diese Chunks physisch gespeichert werden. Metadaten-Knoten stellen außerdem sicher, dass es für die Chunks die erforderliche Anzahl Replikate gibt. Und schließlich protokollieren sie alle wichtigen Ereignisse, die im Cluster auftreten. Acronis Cyber Infrastructure verwendet den Paxos-Konsensusalgorithmus, um die Systemzuverlässigkeit zu gewährleisten. Der Algorithmus sorgt für Fehlertoleranz, wenn die Mehrzahl der Knoten, die Metadaten-Services ausführen, fehlerfrei arbeiten.
Um eine hohe Verfügbarkeit der Metadaten in einer Produktionsumgebung zu ermöglichen, müssen die Metadaten-Services auf mindestens drei Knoten in einem Cluster ausgeführt werden. Wenn bei dieser Konfiguration ein Metadaten-Service ausfallen sollte, können die beiden verbliebenen den Cluster dennoch weiter kontrollieren. Es wird jedoch empfohlen, mindestens fünf Metadaten-Services zu haben, um sicherzustellen, dass der Cluster den gleichzeitigen Ausfall von zwei Knoten ohne Datenverlust überstehen kann.
Der primäre Metadaten-Knoten ist der Master-Knoten im Metadaten-Quorum. Wenn der Master-MDS ausfällt, wird ein anderer verfügbarer MDS als Master ausgewählt.
-
Storage
Die Storage-Knoten führen Chunk-Services (CS) aus, speichern alle Daten in Form von Chunks (Datenblöcke) mit fester Größe und ermöglichen Zugriff auf diese Chunks. Alle Daten-Chunks werden repliziert und diese Replikate auf verschiedenen Storage-Knoten gespeichert, um eine hohe Verfügbarkeit der Daten zu erreichen. Wenn einer der Storage-Knoten ausfällt, stellen die verbliebenen, intakten Storage-Knoten weiterhin die Daten-Chunks bereit, die auf dem ausgefallenen Knoten gespeichert waren. Die Storage-Rolle kann nur einem Server zugewiesen werden, der Laufwerke mit einer bestimmten Kapazität hat.
Storage-Knoten können auch von Daten-Caching und Prüfsummenbildung profitieren:
- Das Daten-Caching verbessert die Cluster-Performance, indem häufig verwendete Daten auf einer SSD zwischengespeichert werden.
-
Die Prüfsummenbildung (Checksumming) generiert jedes Mal Prüfsummen, wenn Daten im Cluster geändert werden. Wenn diese Daten dann später gelesen werden, wird eine neue Prüfsumme berechnet und mit der alten verglichen. Wenn die beiden Prüfsummen nicht übereinstimmen, wird ein erneuter Lesevorgang durchgeführt. Insgesamt wird dadurch die Datenzuverlässigkeit und -Integrität verbessert.
Wenn ein Knoten eine SSD hat, wird diese automatisch für die Speicherung von Prüfsummen konfiguriert, wenn Sie einen solchen Knoten zu einem Cluster hinzufügen. Das ist die empfohlene Einstellung. Wenn ein Knoten jedoch kein SSD-Laufwerk hat, werden die Prüfsummen standardmäßig auf einer herkömmlichen Festplatte (HDD) gespeichert. In diesem Fall muss die Festplatte also eine doppelte I/O-Belastung handhaben, da für jede Lese-/Schreib-Operation auch eine entsprechende Prüfsummen-Lese-/Schreib-Operation durchgeführt wird. Aus diesem Grund können Sie die Prüfsummenbildung auf Knoten ohne SSDs deaktivieren, wenn Sie die Performance (auf Kosten der Datenintegrität) erhöhen wollen. Dies kann besonders bei einem Hot Data-Storage angebracht sein.
- Zusätzliche Rollen:
-
SSD-Journal und Cache
Beschleunigt die Chunck-Lese-/Schreib-Performance durch Schreib-Caches auf dedizierten SSD-Laufwerken. Wir empfehlen, solche SSDs auch für Metadaten zu verwenden. Durch die Verwendung von Write Journals kann die Schreibgeschwindigkeit im Cluster möglicherweise mehr als verdoppelt werden.
-
System
Ein Festplattenlaufwerk pro Knoten, welches für das Betriebssystem reserviert ist und nicht als Storage verwendet werden kann.
Beachten Sie Folgendes:
- Die Zuweisung der Rolle 'System' kann nicht von einem Laufwerk wieder aufgehoben werden.
- Wenn ein physischer Server ein Systemlaufwerk mit einer Kapazität über 100 GB hat, kann diesem Laufwerk zusätzlich die Metadaten-Rolle oder Storage-Rolle zugewiesen werden.
- Es wird empfohlen, die Rolle 'System+Metadaten' einer SSD zuzuweisen. Wenn Sie diese beiden Rollen gemeinsam einem Laufwerk zuweisen, wird dies zu einer mittelmäßige Performance führen, die lediglich für Cold Data geeignet ist (z.B. zu Archivierungszwecken).
- Die Rolle 'System' kann nicht mit den Rollen 'Cache' oder 'Metadaten+Cache' kombiniert werden. Denn die I/O-Anforderungen, die vom Betriebssystem und den Applikationen kommen, und die I/O-Anforderungen, die vom Journaling kommen, würden miteinander konkurrieren und so die jeweiligen Performance-Vorteile zunichte machen.
Neben den Core Storage-Services werden auf den Servern auch Storage-Zugriffspunkte ausgeführt, die Top-Level-Virtualisierungs- und Storage-Services für den Zugriff auf den Storage-Cluster ermöglichen.
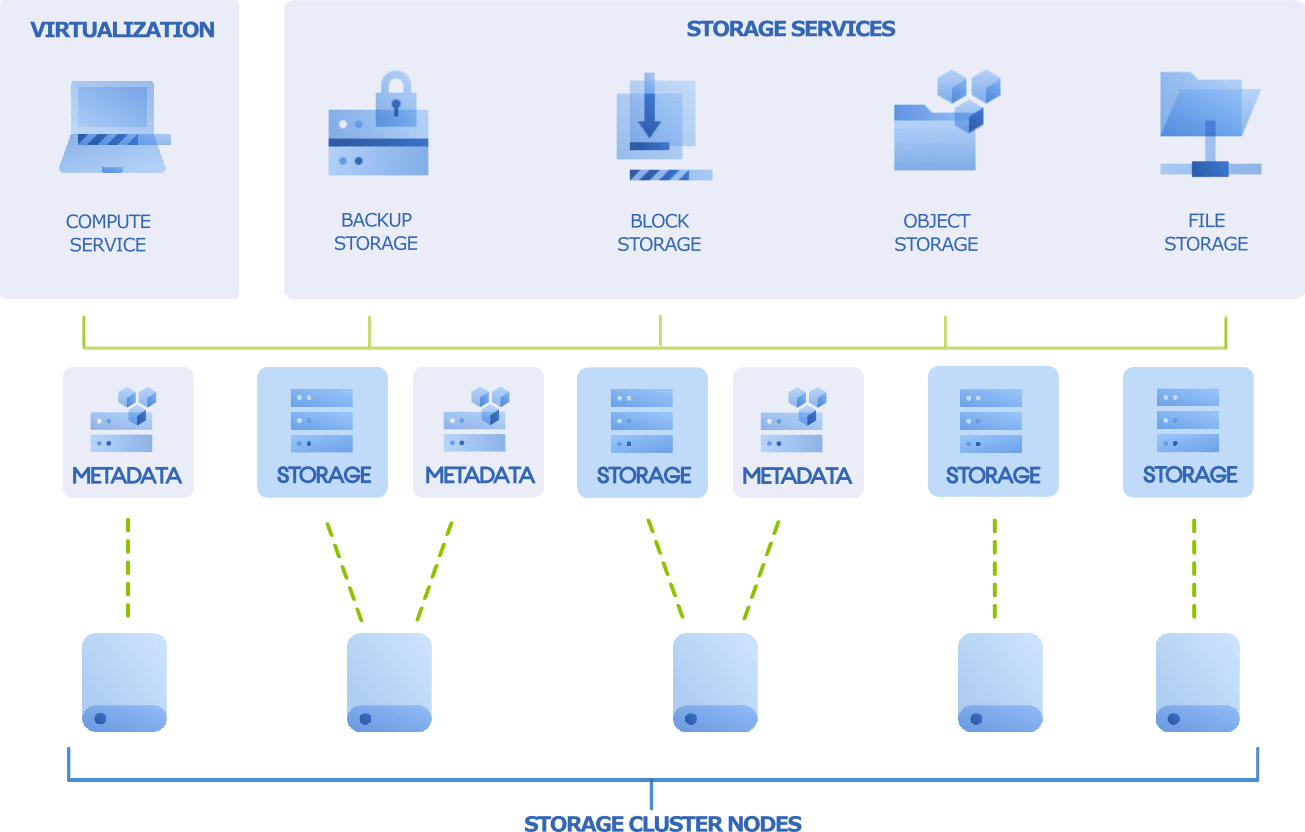
Darüber hinaus kann ein Server, der dem Storage-Cluster beigetreten ist, weder Metadaten- noch Chunk-Services ausführen. In diesem Fall wird der Knoten nur Storage-Zugriffspunkte ausführen und als Storage-Cluster-Client fungieren.