2.6. Understanding Data Redundancy¶
Acronis Cyber Infrastructure protects every piece of data by making it redundant. It means that copies of each piece of data are stored across different storage nodes to ensure that the data is available even if some of the storage nodes are inaccessible.
Acronis Cyber Infrastructure automatically maintains a required number of copies within the cluster and ensures that all the copies are up-to-date. If a storage node becomes inaccessible, copies from it are replaced by new ones that are distributed among healthy storage nodes. If a storage node becomes accessible again after downtime, out-of-date copies on it are updated.
The redundancy is achieved by one of two methods: replication or erasure coding (explained in more detail in the next section). The chosen method affects the size of one piece of data and the number of its copies that will be maintained in the cluster. In general, replication offers better performance while erasure coding leaves more storage space available for data (see table).
Acronis Cyber Infrastructure supports a number of modes for each redundancy method. The following table illustrates data overhead of various redundancy modes. The first three lines are replication and the rest are erasure coding.
| Redundancy mode | Min. number of nodes required | How many nodes can fail without data loss | Storage overhead, % | Raw space needed to store 100GB of data |
|---|---|---|---|---|
| 1 replica (no redundancy) | 1 | 0 | 0 | 100GB |
| 2 replicas | 2 | 1 | 100 | 200GB |
| 3 replicas | 3 | 2 | 200 | 300GB |
| Encoding 1+0 (no redundancy) | 1 | 0 | 0 | 100GB |
| Encoding 1+1 | 2 | 1 | 100 | 200GB |
| Encoding 1+2 | 3 | 2 | 200 | 300GB |
| Encoding 3+1 | 4 | 1 | 33 | 133GB |
| Encoding 3+2 | 5 | 2 | 67 | 167GB |
| Encoding 5+2 | 7 | 2 | 40 | 140GB |
| Encoding 7+2 | 9 | 2 | 29 | 129GB |
| Encoding 17+3 | 20 | 3 | 18 | 118GB |
Note
The 1+0, 1+1, 1+2, and 3+1 encoding modes are meant for small clusters that have insufficient nodes for other erasure coding modes but will grow in the future. As redundancy type cannot be changed once chosen (from replication to erasure coding or vice versa), this mode allows one to choose erasure coding even if their cluster is smaller than recommended. Once the cluster has grown, more beneficial redundancy modes can be chosen.
You choose a data redundancy mode when configuring storage services and creating storage volumes for virtual machines. No matter what redundancy mode you choose, it is highly recommended to be protected against a simultaneous failure of two nodes as that happens often in real-life scenarios.
All redundancy modes allow write operations when one storage node is inaccessible. If two storage nodes are inaccessible, write operations may be frozen until the cluster heals itself.
2.6.1. Redundancy by Replication¶
With replication, Acronis Cyber Infrastructure breaks the incoming data stream into 256MB chunks. Each chunk is replicated and replicas are stored on different storage nodes, so that each node has only one replica of a given chunk.
The following diagram illustrates the 2 replicas redundancy mode.
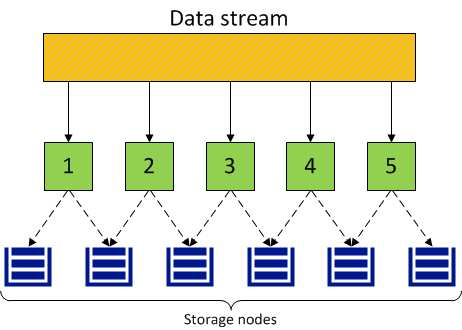
Replication in Acronis Cyber Infrastructure is similar to the RAID rebuild process but has two key differences:
- Replication in Acronis Cyber Infrastructure is much faster than that of a typical online RAID 1/5/10 rebuild. The reason is that Acronis Cyber Infrastructure replicates chunks in parallel, to multiple storage nodes.
- The more storage nodes are in a cluster, the faster the cluster will recover from a disk or node failure.
High replication performance minimizes the periods of reduced redundancy for the cluster. Replication performance is affected by:
- The number of available storage nodes. As replication runs in parallel, the more available replication sources and destinations there are, the faster it is.
- Performance of storage node disks.
- Network performance. All replicas are transferred between storage nodes over network. For example, 1 Gbps throughput can be a bottleneck (see Per-Node Network Requirements and Recommendations).
- Distribution of data in the cluster. Some storage nodes may have much more data to replicate than others and may become overloaded during replication.
- I/O activity in the cluster during replication.
2.6.2. Redundancy by Erasure Coding¶
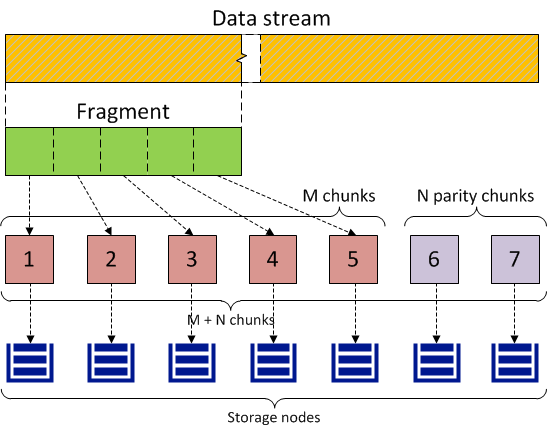
With erasure coding, Acronis Cyber Infrastructure breaks the incoming data stream into fragments of certain size, then splits each fragment into a certain number (M) of 1-megabyte pieces and creates a certain number (N) of parity pieces for redundancy. All pieces are distributed among M+N storage nodes, that is, one piece per node. On storage nodes, pieces are stored in regular chunks of 256MB but such chunks are not replicated as redundancy is already achieved. The cluster can survive failure of any N storage nodes without data loss.
The values of M and N are indicated in the names of erasure coding redundancy modes. For example, in the 5+2 mode, the incoming data is broken into 5MB fragments, each fragment is split into five 1MB pieces and two more 1MB parity pieces are added for redundancy. In addition, if N is 2, the data is encoded using the RAID6 scheme, and if N is greater than 2, erasure codes are used.
The diagram below illustrates the 5+2 mode.
2.6.3. No Redundancy¶
Warning
Danger of data loss!
Without redundancy, singular chunks are stored on storage nodes, one per node. If the node fails, the data may be lost. Having no redundancy is highly not recommended no matter the scenario, unless you only want to evaluate Acronis Cyber Infrastructure on a single server.