2.6. Realización del mantenimiento del nodo¶
Siempre que necesite realizar operaciones de servicio en un nodo de clúster, póngalo en modo de mantenimiento. Cuando lo hace, el nodo deja de distribuir nuevos fragmentos de datos de almacenamiento, pero sigue gestionando operaciones de E/S para servicios de almacenamiento centrales como MDS, CS y caché. Otros servicios del nodo (procesamiento, Backup Gateway, iSCSI, S3 y NFS) pueden reubicarse o dejarse como están durante el mantenimiento. Una vez que el nodo está en el modo de mantenimiento, puede apagarlo y realizar en él operaciones de servicio. Cuando termine, encienda el nodo y vuelva a ponerlo en funcionamiento desde el panel de administración.
Importante
Se recomienda tener cinco servicios MDS en el clúster de almacenamiento. En este caso, cuando un nodo que ejecuta el servicio MDS se apaga durante el mantenimiento, el clúster puede sobrevivir al fallo de otro nodo.
Antes de poner un nodo en modo de mantenimiento, haga lo siguiente:
- Si el nodo hospeda equipos virtuales, estos se reubicarán. Asegúrese de que otros nodos de procesamiento tengan recursos suficientes para acomodar estos equipos virtuales.
- Si el nodo hospeda objetivos de iSCSI, asegúrese de que los iniciadores iSCSI estén configurados para utilizar múltiples direcciones IP desde el mismo grupo de destinos.
- Si el nodo ejecuta una puerta de enlace de S3, elimine sus direcciones IP de los registros DNS de los puntos de acceso S3. En caso contrario, algunos de los clientes de S3 pueden experimentar fallos de conexión.
Para poner un nodo en modo de mantenimiento, haga lo siguiente:
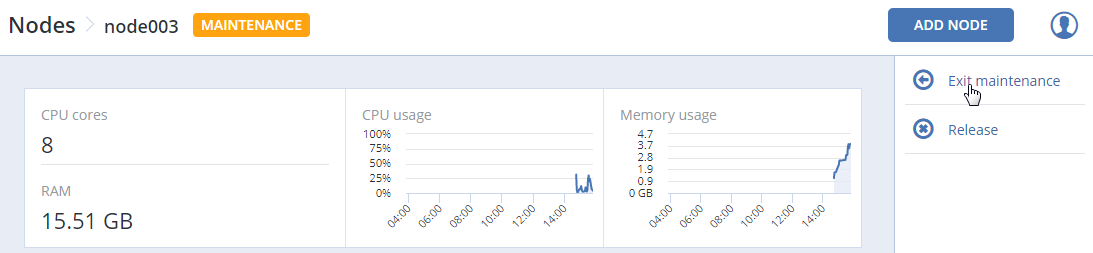
En la pantalla INFRAESTRUCTURA > Nodos, haga clic en el nodo deseado.
En la pantalla de información general del nodo, haga clic en Entrar en mantenimiento.
En la ventana Entrar en mantenimiento, elija si Evacuar o Ignorar las siguientes cargas de trabajo durante el mantenimiento:
- Almacenamiento de bloques. Los grupos de objetivos de iSCSI tienen alta disponibilidad, ejecutándose múltiples objetivos en distintos nodos. Cuando el nodo entra en mantenimiento, el destino que hospeda se detiene y la ruta preferida se traslada a otro nodo del grupo de destinos en un plazo de 60 segundos. De este modo, el servicio no se interrumpe durante el mantenimiento.
- Almacenamiento de bloques (versiones 2.4 o anteriores). Los objetivos de iSCSI antiguos, creados con la versión 2.4 o anterior, se evacuarán del nodo y se migrarán de vuelta después del mantenimiento. Para evitar esto, se recomienda convertir los destinos antiguos en nuevos grupos de destinos, como se describe en Gestión de los objetivos de iSCSI heredados.
Procesamiento. Evacuar equipos virtuales del nodo significa migrarlos en directo uno a uno a otros nodos de procesamiento. Si opta por ignorarlos, seguirán ejecutándose hasta que reinicie o apague un nodo. En este caso, se detendrán y suspenderán, lo que resultará en un tiempo de inactividad. Además, no se iniciarán automáticamente cuando el nodo vuelva a encenderse.
Importante
Los equipos virtuales suspendidos no se pueden evacuar del nodo y se ignorarán.
S3. Puede evacuar los servicios de S3 de este nodo a otros en el clúster de S3, o bien puede ignorarlos. En este último caso, seguirán ejecutándose hasta que reinicie o apague el nodo, lo que provocará un tiempo de inactividad. Se iniciarán automáticamente cuando el nodo vuelva a encenderse.
NFS. Puede evacuar los servicios de NFS de este nodo a otros en el clúster de NFS, o bien puede ignorarlos. En este último caso, seguirán ejecutándose hasta que reinicie o apague el nodo, lo que provocará un tiempo de inactividad. Se iniciarán automáticamente cuando el nodo vuelva a encenderse.
ABGW. Este servicio tiene alta disponibilidad y cuenta con múltiples instancias repartidas por diferentes nodos. Al poner este nodo en modo de mantenimiento se detiene una de las instancias pero las demás siguen funcionando, por lo que el servicio no se interrumpirá.
La autorreparación del clúster es la restauración automática de los datos del clúster de almacenamiento que dejan de estar disponibles cuando un nodo de almacenamiento (o un disco) queda fuera de línea. Si esto sucede durante el mantenimiento, la autorreparación se retrasa (30 minutos de forma predeterminada) para ahorrar recursos del clúster. Si el nodo vuelve a estar en línea antes de que termine el retraso, la autorreparación no será necesaria.
Puede configurar manualmente el tiempo de espera de replicación estableciendo el parámetro
mds.wd.offline_tout_mnt(en milisegundos) con el comandovstorage -c <cluster_name> set-config.Además, cualquier fragmento de datos no redundante en el nodo dejará de estar disponible si este queda fuera de línea. Sin embargo, dichos datos se trasladarán a otros nodos de almacenamiento si marca la casilla Reubicar datos no redundantes. También se pueden trasladar temporalmente a otro nivel si el actual está completo.
En general, todos los CS en el nodo seguirán sirviendo datos incluso en modo de mantenimiento, salvo que el nodo quede fuera de línea. Sin embargo, no se utilizarán para distribuir datos nuevos, por lo que poner el nodo en mantenimiento puede reducir el espacio libre clúster de almacenamiento.
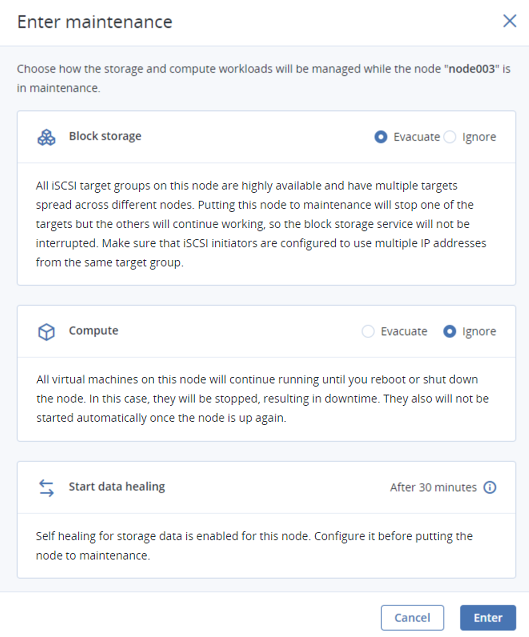
Haga clic en Ingresar.
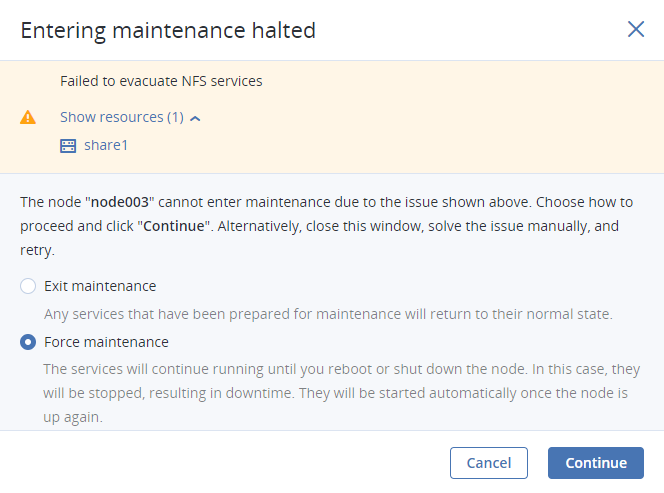
Si no es posible evacuar un servicio del nodo por cualquier motivo, se detendrá la entrada en mantenimiento. Tendrá que decidir cómo procede: puede salir del mantenimiento para que todos los servicios del nodo vuelvan a su estado normal, o puede forzar el mantenimiento para que los servicios que no pudieron evacuarse se detengan durante el reinicio o el apagado del nodo. En la pantalla de información general del nodo, haga clic en Entrar en mantenimiento, elija la acción deseada y haga clic en Continuar.
Los nodos en mantenimiento se pueden poner de nuevo en funcionamiento o liberarse.
Para volver a poner un nodo en funcionamiento, haga clic en Salir de mantenimiento en su pantalla de información general.