5.2. Exporting Storage via S3¶
Acronis Cyber Infrastructure allows you to export cluster disk space to customers in the form of an S3-like object-based storage.
Acronis Cyber Infrastructure is implemented as an Amazon S3-like API, which is one of the most common object storage APIs. End users can work with Acronis Cyber Infrastructure as they work with Amazon S3. You can use the usual applications for S3 and continue working with it after the data migration from Amazon S3 to Acronis Cyber Infrastructure.
Object storage is a storage architecture that enables managing data as objects (like in a key-value storage) as opposed to files in file systems or blocks in a block storage. Except for the data, each object has metadata that describes it as well as a unique identifier that allows finding the object in the storage. Object storage is optimized for storing billions of objects, in particular for application storage, static web content hosting, online storage services, big data, and backups. All of these uses are enabled by object storage thanks to a combination of very high scalability and data availability and consistency.
Compared to other types of storage, the key difference of object storage is that parts of an object cannot be modified, so if the object changes a new version of it is spawned instead. This approach is extremely important for maintaining data availability and consistency. First of all, changing an object as a whole eliminates the issue of conflicts. That is, the object with the latest timestamp is considered to be the current version and that is it. As a result, objects are always consistent, i.e. their state is relevant and appropriate.
Another feature of object storage is eventual consistency. Eventual consistency does not guarantee that reads are to return the new state after the write has been completed. Readers can observe the old state for an undefined period of time until the write is propagated to all the replicas (copies). This is very important for storage availability as geographically distant data centers may not be able to perform data update synchronously (e.g., due to network issues) and the update itself may also be slow as awaiting acknowledges from all the data replicas over long distances can take hundreds of milliseconds. So eventual consistency helps hide communication latencies on writes at the cost of the probable old state observed by readers. However, many use cases can easily tolerate it.
5.2.1. S3 Storage Infrastructure Overview¶
The object storage infrastructure consists of the following entities: object servers (OS), name servers (NS), S3 gateways (GW), and the block-level backend.
These entities run as services on the Acronis Cyber Infrastructure nodes. Each service should be deployed on multiple Acronis Cyber Infrastructure nodes for high availability.
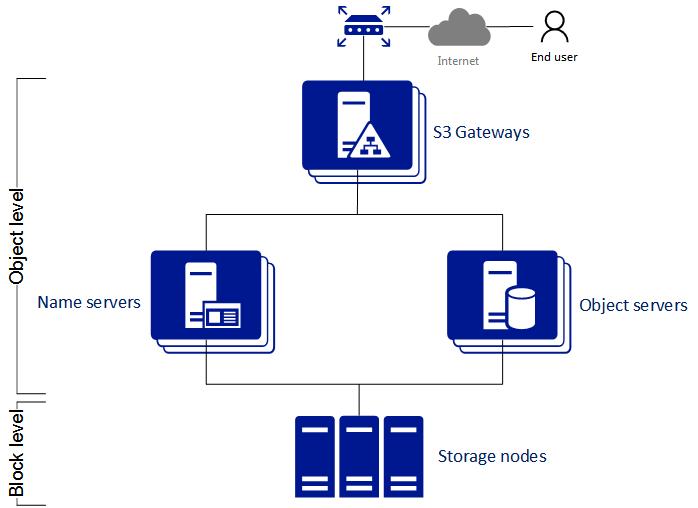
- An object server stores actual object data received from S3 gateway. The data is packed into special containers to achieve high performance. The containers are redundant, you can specify the redundancy mode while configuring object storage. An object server also stores its own data in block storage with built-in high availability.
- A name server stores object metadata received from S3 gateway. Metadata includes object name, size, ACL (access control list), location, owner, and such. Name server (NS) also stores its own data in block storage with built-in high availability.
- An S3 gateway is a data proxy between object storage services and end users. It receives and handles Amazon S3 protocol requests and S3 user authentication and ACL checks. The S3 gateway uses the NGINX web server for external connections and has no data of its own (i.e. is stateless).
- The block-level backend is block storage with high availability of services and data. Since all object storage services run on hosts, no virtual environments (and hence licenses) are required for object storage.
5.2.2. Planning the S3 Cluster¶
Before creating an S3 cluster, do the following:
Define which nodes of the storage cluster will run the S3 storage access point services. It is recommended to have all nodes available in Acronis Cyber Infrastructure run these services.
Configure the network so that the following is achieved:
- All components of the S3 cluster communicate with each other via the S3 private network. All nodes of an S3 cluster must be connected to the S3 private network. Acronis Cyber Infrastructure internal network can be used for this purpose.
- The nodes running S3 gateways must have access to the public network.
- The public network for the S3 gateways must be balanced by an external DNS load balancer.
For more details on network configuration, refer to the Installation Guide.
All components of the S3 cluster should run on multiple nodes for high-availability. Name server and object server components in the S3 cluster are automatically balanced and migrated between S3 nodes. S3 gateways are not automatically migrated; their high availability is based on DNS records. You need to maintain the DNS records manually when adding or removing S3 gateways.
5.2.3. Sample S3 Storage¶
This section shows a sample object storage deployed on top of a storage cluster of five nodes that run various services. The final setup is shown on the figure below.
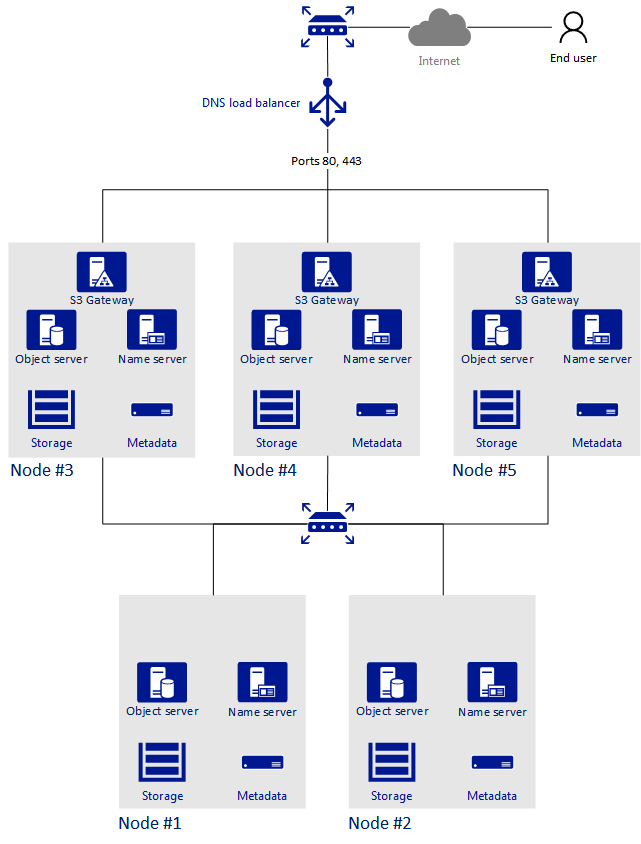
5.2.4. Creating the S3 Cluster¶
To set up object storage services on a cluster node, do the following:
On the INFRASTRUCTURE > Networks screen, make sure that the OSTOR private and S3 public traffic types are added to your networks.
In the left menu, click STORAGE SERVICES > S3.
Select one or more nodes and click Create S3 cluster in the right menu. To create a highly available S3 cluster, select at least three nodes. It is also recommended to enable HA for the management node prior to creating the S3 cluster. See Enabling High Availability for more details.
Make sure the correct network interface is selected in the drop-down list.
If necessary, click the cogwheel icon and configure node’s network interfaces on the Network Configuration screen.
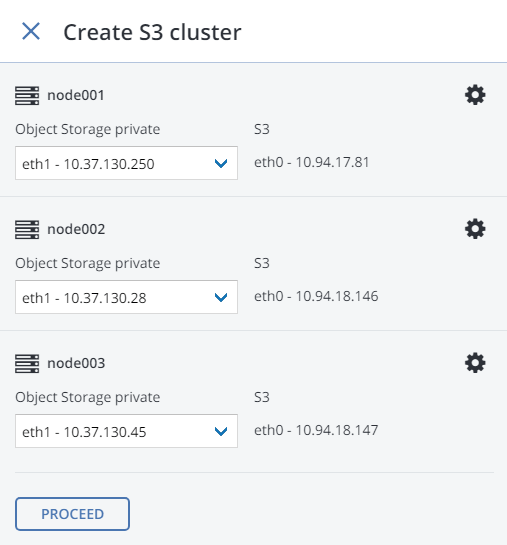
Click Proceed.
On the Volume Parameters tab, select the desired tier, failure domain, and data redundancy mode. For more information, refer to Understanding Storage Tiers, Understanding Failure Domains, and Understanding Data Redundancy.
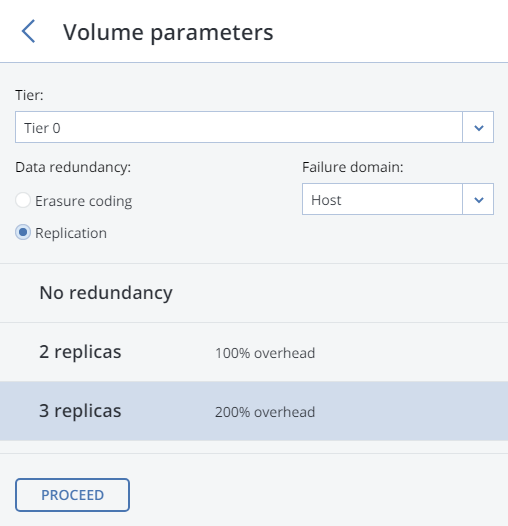
For replication, you can change the redundancy scheme later on the S3 > OVERVIEW > Settings panel. For erasure coding, changing redundancy scheme is disabled, because it may decrease cluster performance. The reason is that re-encoding demands a significant amount of cluster resources for a long period of time. If you still want to change the redundancy scheme, please contact the technical support.
Click Proceed.
Specify the external (publicly resolvable) DNS name for the S3 endpoint that will be used by the end users to access the object storage. For example,
s3.example.com. Click Proceed.Important
Configure your DNS server according to the example suggested in the admin panel.
From the drop-down list, select an S3 endpoint protocol: HTTP, HTTPS or both.
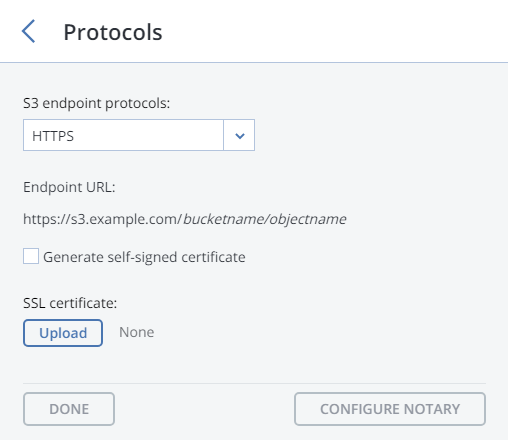
It is recommended to use only HTTPS for production deployments.
If you have selected HTTPS, do one of the following:
Check Generate self-signed certificate to get a self-signed certificate for HTTPS evaluation purposes.
Take note of the following:
- S3 geo-replication requires a certificate from a trusted authority. It does not work with self-signed certificates.
- To access the data in the S3 cluster via a browser, add the self-signed certificate to browser’s exceptions.
Acquire a key and a trusted wildcard SSL certificate for endpoint’s bottom-level domain. For example, the endpoint
s3.storage.example.comwould need a wildcard certificate for*.s3.storage.example.comwith the subject alternative names3.storage.example.com.If you acquired an SSL certificate from an intermediate certificate authority (CA), you should have an end-user certificate along with a CA bundle that contains the root and intermediate certificates. To be able to use these certificates, you need to merge them into a chain first. A certificate chain includes the end-user certificate, the certificates of intermediate CAs, and the certificate of a trusted root CA. In this case, an SSL certificate can only be trusted if every certificate in the chain is properly issued and valid.
For example, if you have an end-user certificate, two intermediate CA certificates, and a root CA certificate, create a new certificate file and add all certificates to it in the following order:
# End-user certificate issued by the intermediate CA 1 -----BEGIN CERTIFICATE----- MIICiDCCAg2gAwIBAgIQNfwmXNmET8k9Jj1X<...> -----END CERTIFICATE----- # Intermediate CA 1 certificate issued by the intermediate CA 2 -----BEGIN CERTIFICATE----- MIIEIDCCAwigAwIBAgIQNE7VVyDV7exJ9ON9<...> -----END CERTIFICATE----- # Intermediate CA 2 certificate issued by the root CA -----BEGIN CERTIFICATE----- MIIC8jCCAdqgAwIBAgICZngwDQYJKoZIhvcN<...> -----END CERTIFICATE----- # Root CA certificate -----BEGIN CERTIFICATE----- MIIDODCCAiCgAwIBAgIGIAYFFnACMA0GCSqG<...> -----END CERTIFICATE-----
Upload the prepared certificate, and, depending on its type, do one of the following:
- specify the passphrase (PKCS#12 files);
- upload the SSL key.
You can change the redundancy mode later on the S3 > OVERVIEW > Protocol settings panel. Click Proceed.
If required, click Configure Acronis Notary and specify Notary DNS name and Notary user key.
Click Done to create an S3 cluster.
After the S3 cluster is created, open the S3 Overview screen to view cluster status, hostname, used disk capacity, the number of users, I/O activity, and the state of S3 services.
To check if the S3 cluster is successfully deployed and can be accessed by users, visit https://<S3_DNS_name> or http://<S3_DNS_name> in your browser. You should receive the following XML response:
<Error>
<Code>AccessDenied</Code>
<Message/>
</Error>
To start using the S3 storage, you will also need to create at least one S3 user.
5.2.5. Managing S3 Users¶
The concept of S3 user is one of the base concepts of object storage along with those of object and bucket (container for storing objects). The Amazon S3 protocol uses a permission model based on access control lists (ACLs) where each bucket and each object is assigned an ACL that lists all users with access to the given resource and the type of this access (read, write, read ACL, write ACL). The list of users includes the entity owner assigned to every object and bucket at creation. The entity owner has extra rights compared to other users. For example, the bucket owner is the only one who can delete that bucket.
User model and access policies implemented in Acronis Cyber Infrastructure comply with the Amazon S3 user model and access policies.
User management scenarios in Acronis Cyber Infrastructure are largely based on the Amazon Web Services user management and include the following operations: create, query, and delete users as well as generate and revoke user access key pairs.
5.2.5.1. Adding S3 Users¶
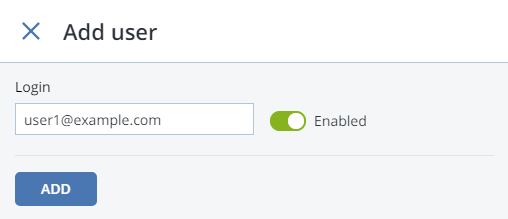
To add an S3 user, do the following:
On the STORAGE SERVICES > S3 > USERS screen, click ADD USER.
Specify a valid email address as login for the user and click ADD.
5.2.5.2. Managing S3 Access Key Pairs¶
Each S3 user has one or two key pairs (access key and secret key) for accessing the S3 cloud. You can think of the access key as login and the secret key as password. (For more information about S3 key pairs, refer to the Amazon documentation.) The access keys are generated and stored locally in the storage cluster on S3 name servers. Each user can have up to two key pairs. It is recommended to periodically revoke old and generate new access key pairs.
To view, add, or revoke the S3 access key pairs for an S3 user, do the following:
Select a user in the list and click Keys.
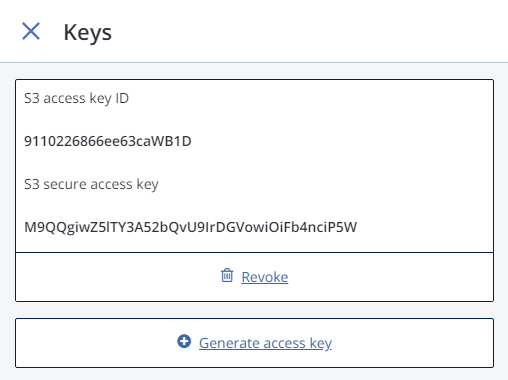
The existing keys will be shown on the Keys panel.
- To revoke a key, click Revoke.
- To add a new key, click Generate access key.
To access a bucket, a user will need the following information:
admin panel IP address,
DNS name of the S3 cluster specified during configuration,
S3 access key ID,
S3 secret access key,
SSL certificate if the HTTPS protocol was chosen during configuration.
The certificate file can be found in the
/etc/nginx/ssl/directory on any node hosting the S3 gateway service.
To automatically log in to S3 with user credentials using the generated keys, select a user and click Browse.
To Browse using an SSL certificate, make sure it is valid or, in case of a self-signed one, add it to browser’s exceptions.
5.2.6. Managing S3 Buckets¶
All objects in Amazon S3-like storage are stored in containers called “buckets”. Buckets are addressed by names that are unique in the given object storage, so an S3 user of that object storage cannot create a bucket that has the same name as a different bucket in the same object storage. Buckets are used to:
- group and isolate objects from those in other buckets,
- provide ACL management mechanisms for objects in them,
- set per-bucket access policies, for example, versioning in the bucket.
In the current version of Acronis Cyber Infrastructure, you can enable and disable Acronis Notary for object storage buckets and monitor the space used by them on the STORAGE SERVICES > S3 > Buckets screen. You cannot create and manage object storage buckets from Acronis Cyber Infrastructure admin panel. However, you can do it via the Acronis Cyber Infrastructure user panel or by using a third-party application. For example, the applications listed below allow you to perform the following actions:
- CyberDuck: create and manage buckets and their contents.
- MountainDuck: mount object storage as a disk drive and manage buckets and their contents.
- Backup Exec: store backups in the object storage.
5.2.6.1. Listing S3 Bucket Contents¶
You can list bucket contents with a web browser. To do this, visit the URL that consists of the external DNS name for the S3 endpoint that you specified when creating the S3 cluster and the bucket name. For example, mys3storage.example.com/mybucket or mybucket.mys3storage.example.com (depending on DNS configuration).
You can also copy the link to bucket contents by right-clicking it in CyberDuck, and then selecting Copy URL.
5.2.6.2. Managing Acronis Notary in S3 Buckets¶
Acronis Cyber Infrastructure offers integration with the Acronis Notary service to leverage blockchain notarization and ensure the immutability of data saved in object storage clusters. To use Acronis Notary in user buckets, you need to set it up in the S3 cluster and enable it for said buckets.
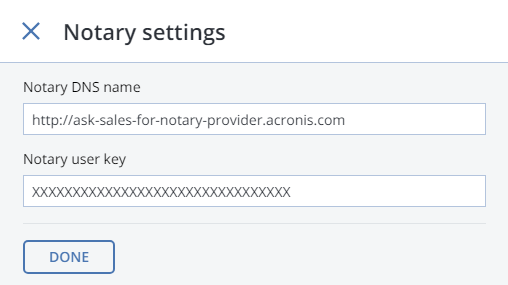
To set up Acronis Notary, do the following:
Get the DNS name and the user key for the notary service from your sales contact.
On the STORAGE SERVICES > S3 screen, click Notary settings.
On the Notary Settings screen, specify the DNS name and user key in the respective fields and click Done.
To enable or disable blockchain notarization for a bucket, select a bucket on the STORAGE SERVICES > S3 > Buckets screen and click Enable Notary or Disable Notary, respectively.
Notarization is disabled for new buckets by default.
Once you enable notarization for a bucket, certificates are created automatically only for the newly uploaded files. The previously uploaded files are left unnotarized. Once a file was notarized, it will remain notarized even if you disable notarization later.
5.2.7. Best Practices for Using S3 in Acronis Cyber Infrastructure¶
This section offers recommendations on how to best use the S3 feature of Acronis Cyber Infrastructure.
5.2.7.1. S3 Bucket and Key Naming Policies¶
It is recommended to use bucket names that comply with DNS naming conventions:
- can be from 3 to 63 characters long
- must start and end with a lowercase letter or number
- can contain lowercase letters, numbers, periods (.), hyphens (-), and underscores (_)
- can be a series of valid name parts (described previously) separated by periods
An object key can be a string of any UTF-8 encoded characters up to 1024 bytes long.
5.2.7.2. Improving Performance of PUT Operations¶
Object storage supports uploading objects as large as 5 GB per single PUT request (5 TB via multipart upload). Upload performance can be improved by splitting large objects into pieces and uploading them concurrently (thus dividing the load between multiple OS services) with multipart upload API.
It is recommended to use multipart uploads for objects larger than 5 MB.
5.2.8. Replicating S3 Data Between Datacenters¶
Acronis Cyber Infrastructure can store replicas of S3 cluster data and keep them up-to-date in multiple geographically distributed datacenters with S3 clusters based on Acronis Cyber Infrastructure. Geo-replication reduces the response time for local S3 users accessing the data in a remote S3 cluster or remote S3 users accessing the data in a local S3 cluster as they do not need to have an Internet connection.
Geo-replication schedules the update of the replicas as soon as any data is modified. Geo-replication performance depends on the speed of Internet connection, the redundancy mode, and cluster performance.
If you have multiple datacenters with enough free space, it is recommended to set up geo-replication between S3 clusters residing in these datacenters.
Important
Each cluster must have its own SSL certificate signed by a global certificate authority.
To set up geo-replication between S3 clusters, exchange tokens between datacenters as follows:
In the admin panel of a remote datacenter, open the STORAGE SERVICES > S3 > GEO-REPLICATION screen.
In the section of the home S3 cluster, click TOKEN and, on the Get token panel, copy the token.
In the admin panel of the local datacenter, open the STORAGE SERVICES > S3 > GEO-REPLICATION screen and click ADD DATACENTER.
Enter the copied token and click Done.
Configure the remote S3 cluster the same way.
5.2.9. Monitoring S3 Access Points¶
The S3 monitoring screen enables you to inspect the availability of each S3 component as well as the performance of NS and OS services (which are highly available).
If you see that some of the NS or OS services are offline, it means that the S3 access point does not function properly. In this case, please contact the techical support or consult the Administrator’s Command Line Guide. S3 gateways are not highly available, but DNS load balancing should be enough to avoid downtime if the gateway fails.
The performance charts represent the number of operations that the OS/NS services are performing.
5.2.10. Releasing Nodes from S3 Clusters¶
Before releasing a node, make sure that the cluster has enough nodes running name and object servers as well as gateways left.
Warning
When the last node in the S3 cluster is removed, the cluster is destroyed, and all the data is deleted.
To release a node from an S3 cluster, do the following:
- On the STORAGE SERVICES > S3 > Nodes screen, check the box of the node to release.
- Click Release.
5.2.11. Supported Amazon S3 Features¶
Besides basic Amazon S3 operations like GET, PUT, COPY, DELETE, the Acronis Cyber Infrastructure implementation of the Amazon S3 protocol supports the following features:
- multipart upload
- access control lists (ACLs)
- versioning
- signed URLs
- object locking
- geo-replication
- blockchain notarization via Acronis Notary
All the supported Amazon S3 operations, headers, and authentication schemes are listed further.
5.2.11.1. Supported Amazon S3 REST Operations¶
The following Amazon S3 REST operations are currently supported by the Acronis Cyber Infrastructure implementation of the Amazon S3 protocol:
Supported service operations: GET Service.
Supported bucket operations:
- DELETE/HEAD/PUT Bucket
- GET Bucket (List Objects)
- GET/PUT Bucket acl
- GET Bucket location (returns
US East) - GET Bucket Object versions
- GET/PUT Bucket versioning
- List Multipart Uploads
Supported object operations:
- DELETE/GET/HEAD/POST/PUT Object
- Delete Multiple Objects
- PUT Object - Copy
- GET/PUT Object acl
- Delete Multiple Objects
- Abort Multipart Upload
- Complete Multipart Upload
- Initiate Multipart Upload
- List Parts
- Upload Part
Note
For more information on Amazon S3 REST operations, see Amazon S3 REST API documentation.
5.2.11.2. Supported Amazon Request Headers¶
The following Amazon S3 REST request headers are currently supported by the Acronis Cyber Infrastructure implementation of the Amazon S3 protocol:
- Authorization
- Content-Length
- Content-Type
- Content-MD5
- Date
- Host
- x-amz-content-sha256
- x-amz-date
- x-amz-security-token
- x-amz-object-lock-retain-until-date
- x-amz-object-lock-mode
- x-amz-object-lock-legal-hold
- x-amz-bypass-governance-retention
- x-amz-bucket-object-lock-enabled
The following Amazon S3 REST request headers are ignored:
- Expect
- x-amz-security-token
Note
For more information on Amazon S3 REST request headers, see the Amazon S3 REST API documentation.
5.2.11.3. Supported Amazon Response Headers¶
The following Amazon S3 REST response headers are currently supported by the Acronis Cyber Infrastructure implementation of the Amazon S3 protocol:
- Content-Length
- Content-Type
- Connection
- Date
- ETag
- x-amz-delete-marker
- x-amz-request-id
- x-amz-version-id
- x-amz-object-lock-retain-until-date
- x-amz-object-lock-mode
- x-amz-object-lock-legal-hold
The following Amazon S3 REST response headers are not used:
- Server
- x-amz-id-2
Note
For more information on Amazon S3 REST response headers, see the Amazon S3 REST API documentation.
5.2.11.4. Supported Amazon Error Response Headers¶
The following Amazon S3 REST error response headers are currently supported by the Acronis Cyber Infrastructure implementation of the Amazon S3 protocol:
- Code
- Error
- Message
- RequestId
- Resource
The following Amazon S3 REST error response headers are not supported:
- RequestId (not used)
- Resource
Note
For more information on Amazon S3 REST response headers, see the Amazon S3 REST API documentation.
5.2.11.5. Supported Authentication Schemes¶
The following authentication schemes are supported by the Acronis Cyber Infrastructure implementation of the Amazon S3 protocol:
The following authentication methods are supported by the Acronis Cyber Infrastructure implementation of the Amazon S3 protocol:
The following authentication method is not supported: