6.6. Monitoring Event Logs¶
You can use the vstorage -c <cluster_name> top utility to monitor significant events happening in the storage cluster. For example:
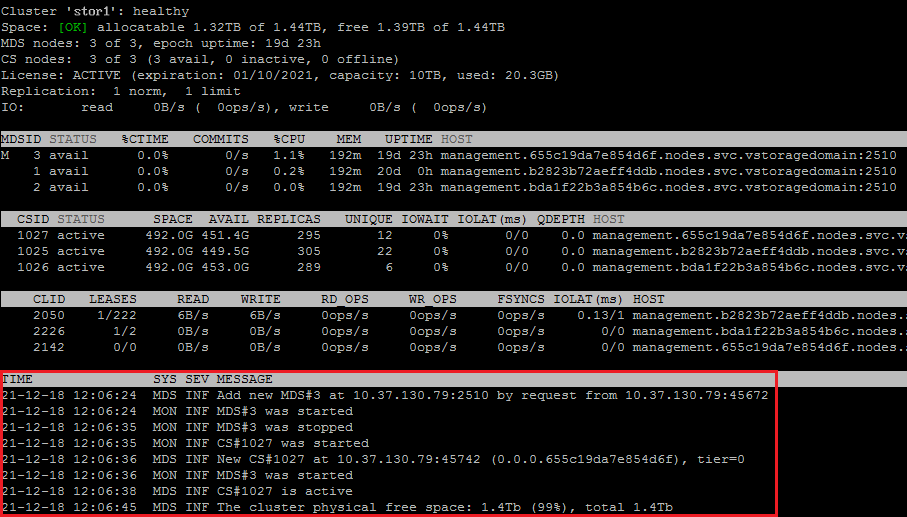
The command above shows the latest events in the stor1 cluster. The information on events (highlighted in red) is given in a table with the following columns:
- TIME
- Time of event.
- SYS
- Component of the cluster where the event happened (e.g., MDS for an MDS server or JRN for local journal).
- SEV
- Event severity.
- MESSAGE
- Event description.
The following table lists basic events displayed when you run the vstorage top utility.
| Event | Severity | Description |
|---|---|---|
| MDS#<N> (<addr>:<port>) lags behind for more than 1000 rounds | JRN err | Generated by the MDS master server when it detects that MDS#<N> is stale. This message may indicate that some MDS server is very slow and lags behind. |
| MDS#<N> (<addr>:<port>) didn’t accept commits for M sec | JRN err | Generated by the MDS master server if MDS#<N> did not accept commits for M seconds. MDS#<N> gets marked as stale. This message may indicate that the MDS service on MDS#<N> is experiencing a problem. The problem may be critical and should be resolved as soon as possible. |
| MDS#<N> (<addr>:<port>) state is outdated and will do a full resync | JRN err | Generated by the MDS master server when MDS#<N> will do a full resync. MDS#<N> gets marked as stale. This message may indicate that some MDS server was too slow or disconnected for such a long time that it is not really managing the state of metadata and has to be resynchronized. The problem may be critical and should be resolved as soon as possible. |
| MDS#<N> at <addr>:<port> became master | JRN info | Generated every time a new MDS master server is elected in the cluster. Frequent changes of MDS masters may indicate poor network connectivity and may affect the cluster operation. |
| The cluster is healthy with N active CS | MDS info | Generated when the cluster status changes to healthy or when a new MDS master server is elected. This message indicates that all chunk servers in the cluster are active and the number of replicas meets the set cluster requirements. |
| The cluster is degraded with N active, M inactive, K offline CS | MDS warn | Generated when the cluster status changes to degraded or when a new MDS master server is elected. This message indicates that some chunk servers in the cluster are
|
| The cluster failed with N active, M inactive, K offline CS (mds.wd.max_offline_cs=<n>) | MDS err | Generated when the cluster status changes to failed or when a new MDS master server is elected. This message indicates that the number of
offline chunk servers exceeds
|
| The cluster is filled up to <N>% | MDS info/warn | Shows the current space usage in the cluster. A warning is generated if the disk space consumption equals or exceeds 80%. It is important to have spare disk space for data replicas if one of the chunk servers fails. |
| Replication started, N chunks are queued | MDS info | Generated when the cluster starts automatic data replication to recover the missing replicas. |
| Replication completed | MDS info | Generated when the cluster finishes automatic data replication. |
| CS#<N> has reported hard error on path | MDS warn | Generated when the chunk server CS#<N> detects disk data corruption. You are recommended to check the hardware for errors and replace corrupted disks as soon as possible. |
| CS#<N> has not registered during the last T sec and is marked as inactive/offline | MDS warn | Generated when the chunk server CS#<N> has been unavailable for a while. In this case, the chunk server first gets marked as inactive. After 5 minutes, the state is changed to offline, which starts automatic replication of data to restore the replicas that were stored on the offline chunk server. |
| Failed to allocate N replicas for ‘path’ by request from <addr>:<port> - K out of M chunks servers are available | MDS warn | Generated when the cluster cannot allocate chunk replicas, for example, when it runs out of disk space. |
| Failed to allocate N replicas for ‘path’ by request from <addr>:<port> since only K chunk servers are registered | MDS warn | Generated when the cluster cannot allocate chunk replicas because not enough chunk servers are registered in the cluster. |