2.2. Explicación de las políticas de almacenamiento¶
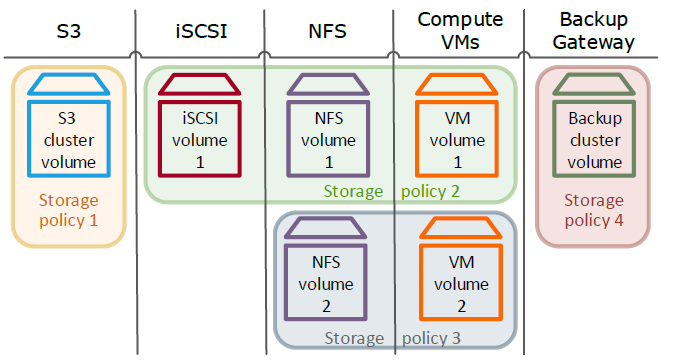
Acronis Cyber Infrastructure puede utilizarse en los siguientes escenarios: almacenamiento de bloques iSCSI, almacenamiento de archivos NFS, almacenamiento de objetos S3, copias de seguridad de almacenamiento: (para almacenar copias de seguridad creadas en soluciones de Acronis Cyber Backup). También puede utilizar su hipervisor incorporado para crear equipos virtuales de procesamiento (VM). En todos estos escenarios, la unidad común de datos es el volumen. En el servicio de procesamiento, un volumen es una unidad de disco virtual que se puede conectar a un equipo virtual. En iSCSI, S3, Backup Gateway, y NFS, un volumen es una unidad de datos que se utiliza para exportar espacio. En todos los casos, para crear un volumen necesita definir el nodo de redundancia, el nivel y el dominio para casos de fallo. Estos parámetros conforman una política de almacenamiento que define la redundancia de un volumen y dónde tiene que ubicarse.
Redundancia significa que los datos se almacenan en distintos nodos de almacenamiento y están disponibles incluso si algunos de los nodos fallan. Si un nodo de almacenamiento deja de ser accesible, las copias de datos que se encuentran en el mismo se sustituyen por otras nuevas que se distribuyen entre los nodos de almacenamiento en buen estado. Los datos desactualizados se actualizan cuando el nodo de almacenamiento vuelve a estar en línea después de un tiempo de inactividad.
Con replicación, Acronis Cyber Infrastructure fragmenta un volumen en elementos de tamaño establecido (bloques de datos). Cada bloque se replica tantas veces como se establece en la política de almacenamiento. Las réplicas se almacenan en distintos nodos de almacenamiento en el caso de que el dominio para casos de fallo sea un servidor, de forma que cada uno solo tenga una réplica de un bloque específico.
El flujo de datos entrante se divide en fragmentos de cierto tamaño con la codificación de borrado o simplemente con la codificación. Los fragmentos no se copian por sí mismos, sino que se agrupa un número determinado (M) de dichos fragmentos y se crea un número determinado (N) de partes de paridad para la redundancia. Todas las partes se distribuyen entre nodos de almacenamiento M+N seleccionados de entre todos los nodos disponibles. Los datos pueden resistir el fallo de cualquier nodo de almacenamiento N sin que se pierdan. Los valores de M y N se indican en los nombres de los modos de redundancia de codificación de borrado. Por ejemplo, en el modo 5+2, los datos entrantes se dividen en cinco fragmentos y se añaden dos partes de paridad (del mismo tamaño) para obtener la redundancia. Consulte la Guía del administrador <admins_guide:index> para obtener más información sobre la redundancia, la sobrecarga de datos, el número de nodos y los requisitos de espacio sin procesar.
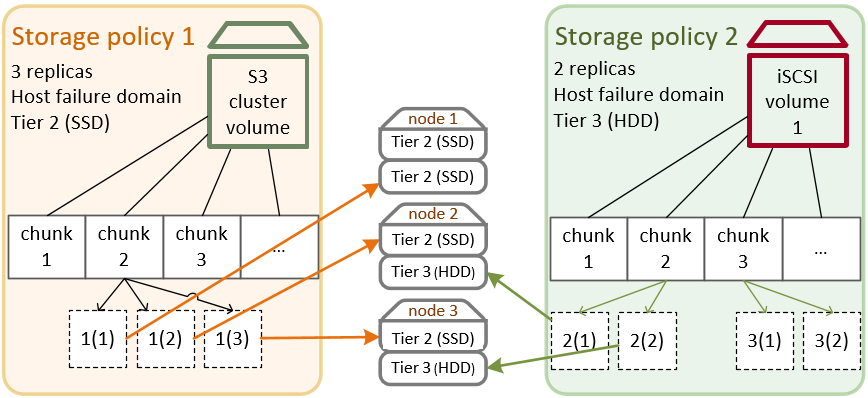
Para entender mejor la política de almacenamiento, veamos sus principales componentes (niveles, dominios para casos de fallo y redundancia) para una situación de ejemplo. Por ejemplo, tiene tres nodos con un número de nodos de almacenamiento: unidades SSD rápidas y unidades HDD de alta capacidad. El nodo 1 solo tiene unidades SSD. Los nodos 2 y 3 tienen tanto unidades SSD como HDD. Desea exportar espacio de almacenamiento mediante iSCSI y S3, por lo que necesita definir una política de almacenamiento adecuada para cada carga de trabajo.
- El primer parámetro, el nivel, define un grupo de discos unidos por criterios, normalmente el tipo de unidad de disco, adaptados a una carga de trabajo de almacenamiento específica. En este ejemplo de escenario, puede agrupar sus unidades de disco SSD en el nivel 2 y las unidades HDD en el nivel 3. Puede asignar un disco a un nivel al crear un clúster de almacenamiento o añadir nodos al mismo (consulte Creación del clúster de almacenamiento). Tenga en cuenta que solo los nodos 2 y 3 tienen unidades HDD y que se utilizarán en el nivel 3. Las unidades SSD del primer nodo no pueden utilizarse en el nivel 3.
- El segundo parámetro, el dominio de fallo, define un ámbito en el que un conjunto de servicios de almacenamiento puede fallar de forma correlacionada. El dominio de fallos predeterminado es un servidor. Los bloques de datos se copian en diferentes nodos de almacenamiento, una copia por nodo. Si un nodo falla, se puede acceder a los datos a través de los nodos en buen estado. Un disco también puede ser un dominio para casos de fallo, aunque solo es importante en los clústeres de un nodo. Como tiene tres nodos en este escenario, le recomendamos elegir el servidor como dominio para casos de fallo.
- El tercer parámetro, la redundancia, se debe configurar de acuerdo con los discos y los niveles. En el ejemplo de evaluación tiene tres nodos y todos cuentan con unidades SSD en el nivel 2. Por lo tanto, si selecciona el nivel 2 en su política de almacenamiento, podrá utilizar los tres nodos para las réplicas 1, 2 y 3. Sin embargo, solo dos de sus nodos tienen unidades HDD en el nivel 3. Por lo tanto, si selecciona el nivel 3 en su política de almacenamiento, solo podrá almacenar las réplicas 1 y 2 en los dos nodos. En ambos casos, también puede utilizar la codificación, pero para nuestra evaluación utilizaremos solo la replicación: tres réplicas para las unidades SSD y dos réplicas para las unidades HDD.
En resumen, las políticas de almacenamiento que obtiene son: